mirror of
https://github.com/dholerobin/Lecture_Notes.git
synced 2025-09-13 13:52:12 +00:00
added sql and lld1 notes to master
This commit is contained in:
@@ -0,0 +1,172 @@
|
||||
# Asynchronous Programming vs Multithreading
|
||||
---
|
||||
|
||||
|
||||
## Asynchronous Programming
|
||||
Asynchronous programming is a programming paradigm that allows tasks to be executed independently without blocking the main thread. It focuses on managing the flow of the program by handling tasks concurrently and efficiently. It's commonly used to improve the responsiveness of applications by avoiding long-running operations that might otherwise cause the user interface to freeze. Java provides several mechanisms for asynchronous programming, and in this tutorial, we'll cover the basics using - Threads, CompletableFuture and the ExecutorService.
|
||||
|
||||
### 1. Threads
|
||||
We can create a new thread to perform any operation asynchronously. With the release of lambda expressions in Java 8, it’s cleaner and more readable.
|
||||
|
||||
Let’s create a new thread that computes and prints the factorial of a number:
|
||||
```java
|
||||
public class ThreadExample {
|
||||
public static int factorial(int n){
|
||||
|
||||
System.out.println(Thread.currentThread().getName() + "is running");
|
||||
|
||||
try{
|
||||
Thread.sleep(2000);
|
||||
}
|
||||
catch(InterruptedException e){
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
int ans=1;
|
||||
for(int i=1;i<n;i++){
|
||||
ans = ans*i;
|
||||
}
|
||||
System.out.println(Thread.currentThread().getName() + "is finished");
|
||||
return ans;
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
|
||||
int number = 5;
|
||||
Thread newThread = new Thread(()->{
|
||||
System.out.println("Factorial of 5 " + factorial(number));
|
||||
});
|
||||
newThread.start();
|
||||
System.out.println("Main is still running-1");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 2. FutureTask
|
||||
Since Java 5, the Future interface provides a way to perform asynchronous operations using the FutureTask. We can use the submit method of the ExecutorService to perform the task asynchronously and return the instance of the FutureTask.
|
||||
```java
|
||||
ExecutorService threadpool = Executors.newCachedThreadPool();
|
||||
Future<Long> futureTask = threadpool.submit(() -> factorial(number));
|
||||
|
||||
while (!futureTask.isDone()) {
|
||||
System.out.println("FutureTask is not finished yet...");
|
||||
}
|
||||
long result = futureTask.get(); //Blocking Code
|
||||
threadpool.shutdown();
|
||||
```
|
||||
Here we’ve used the `isDone` method provided by the Future interface to check if the task is completed. Once finished, we can retrieve the result using the get method.
|
||||
|
||||
### 3. CompletableFuture
|
||||
CompletableFuture is a class introduced in Java 8 that provides a way to perform asynchronous operations and handle their results using a fluent API. Java 8 introduced CompletableFuture with a combination of a Future and CompletionStage. It provides various methods like supplyAsync, runAsync, and thenApplyAsync for asynchronous programming.
|
||||
|
||||
**Example-1**
|
||||
```java
|
||||
import java.util.concurrent.CompletableFuture;
|
||||
import java.util.concurrent.ExecutionException;
|
||||
|
||||
public class CompletableFutureExample {
|
||||
public static void main(String[] args) {
|
||||
// Create a CompletableFuture
|
||||
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
|
||||
// Simulate a time-consuming task
|
||||
try {
|
||||
Thread.sleep(2000);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
return "Hello, CompletableFuture!";
|
||||
});
|
||||
|
||||
// Attach a callback to handle the result
|
||||
future.thenAccept(result -> System.out.println("Result: " + result));
|
||||
|
||||
// Wait for the CompletableFuture to complete (not recommended in real applications)
|
||||
try {
|
||||
future.get();
|
||||
} catch (InterruptedException | ExecutionException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
In this example, we use `CompletableFuture.supplyAsync` to perform a task asynchronously. The thenAccept method is used to attach a callback that will be executed when the asynchronous task completes.
|
||||
|
||||
**Example-2**
|
||||
```
|
||||
CompletableFuture<Long> completableFuture = CompletableFuture.supplyAsync(() -> factorial(number));
|
||||
while (!completableFuture.isDone()) {
|
||||
System.out.println("CompletableFuture is not finished yet...");
|
||||
}
|
||||
long result = completableFuture.get();
|
||||
```
|
||||
We don’t need to use the ExecutorService explicitly. The CompletableFuture internally uses ForkJoinPool to handle the task asynchronously. Thus, it makes our code a lot cleaner.
|
||||
|
||||
|
||||
### Uses of Asynchronous Programming:
|
||||
|
||||
- IO-Intensive Operations: Asynchronous programming is often used for tasks that involve waiting for external resources, such as reading from or writing to files, making network requests, or interacting with databases.
|
||||
- Responsive UI: In GUI applications, asynchronous programming helps in maintaining a responsive user interface by executing time-consuming tasks in the background.
|
||||
|
||||
- Callback Mechanism: Asynchronous programming often uses callbacks or combinators to specify what should happen once a task is complete.
|
||||
|
||||
- Composability: It emphasizes composability, allowing developers to chain together multiple asynchronous operations.
|
||||
|
||||
```java
|
||||
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "Hello, CompletableFuture!");
|
||||
|
||||
// Attach a callback to handle the result
|
||||
future.thenAccept(result -> System.out.println("Result: " + result));
|
||||
```
|
||||
|
||||
### Multi-threading
|
||||
Multithreading involves the concurrent execution of two or more threads to achieve parallelism. It is a fundamental concept for optimizing CPU-bound tasks and improving overall system performance. Key Components for achieving multithreading in Java are thread class and Executor Framework.
|
||||
|
||||
- Thread Class: Java provides the Thread class for creating and managing threads.
|
||||
- Executor Framework: The ExecutorService and related interfaces offer a higher-level abstraction for managing thread pools.
|
||||
|
||||
### Use Case of Multithreading:
|
||||
|
||||
- CPU-Intensive Operations: Multithreading is suitable for tasks that are CPU-bound and can benefit from parallel execution, such as mathematical computations.
|
||||
|
||||
- Parallel Processing: Multithreading can be used to perform multiple tasks simultaneously, making efficient use of available CPU cores.
|
||||
|
||||
### Shared State and Synchronization:
|
||||
|
||||
- Shared State: In multithreading, threads may share data, leading to potential issues like race conditions and data corruption.
|
||||
|
||||
- Synchronization: Techniques like synchronization, locks, and atomic operations are used to ensure proper coordination between threads.
|
||||
|
||||
Example using ExecutorService:
|
||||
```java
|
||||
ExecutorService executorService = Executors.newFixedThreadPool(2);
|
||||
|
||||
// Submit a task for execution
|
||||
Future<String> future = executorService.submit(() -> "Hello, ExecutorService!");
|
||||
|
||||
// Retrieve the result when ready
|
||||
try {
|
||||
String result = future.get(); // This will block until the result is available
|
||||
System.out.println("Result: " + result);
|
||||
} catch (Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
|
||||
// Shutdown the ExecutorService
|
||||
executorService.shutdown();
|
||||
```
|
||||
|
||||
### Summary
|
||||
### Asynchronous Programming:
|
||||
- Focuses on non-blocking execution.
|
||||
- Primarily used for IO-bound tasks and maintaining responsive applications.
|
||||
- Utilizes higher-level abstractions like CompletableFuture.
|
||||
- Emphasizes composability and chaining of asynchronous operations.
|
||||
|
||||
### Multithreading:
|
||||
- Focuses on parallelism for CPU-bound tasks.
|
||||
- Suitable for tasks that can be executed concurrently.
|
||||
- Utilizes threads and thread pools, managed by the Thread class and ExecutorService.
|
||||
- Requires attention to synchronization and shared state management.
|
||||
|
||||
In some scenarios, asynchronous programming and multithreading can be used together to achieve both parallelism and non-blocking execution, depending on the nature of the tasks in an application.
|
||||
@@ -0,0 +1,82 @@
|
||||
# Concurrent Hashmap
|
||||
|
||||
Java Collections provides various data structures for working with key-value pairs. The commonly used ones are -
|
||||
- **Hashmap** (Non-Synchronised, Not Thread Safe)
|
||||
- discuss the Synchronized Hashmap method
|
||||
|
||||
- **Hashtable** (Synchronised, Thread Safe)
|
||||
- locking over entire table
|
||||
|
||||
- **Concurrent Hashmap** (Synchronised, Thread Safe, Higher Level of Concurrency, Faster)
|
||||
- locking at bucket level, fine grained locking
|
||||
|
||||
**Hashmap and Synchronised Hashmap Method**
|
||||
Synchronization is the process of establishing coordination and ensuring proper communication between two or more activities. Since a HashMap is not synchronized which may cause data inconsistency, therefore, we need to synchronize it. The in-built method ‘Collections.synchronizedMap()’ is a more convenient way of performing this task.
|
||||
|
||||
A synchronized map is a map that can be safely accessed by multiple threads without causing concurrency issues. On the other hand, a Hash Map is not synchronized which means when we implement it in a multi-threading environment, multiple threads can access and modify it at the same time without any coordination. This can lead to data inconsistency and unexpected behavior of elements. It may also affect the results of an operation.
|
||||
|
||||
Therefore, we need to synchronize the access to the elements of Hash Map using ‘synchronizedMap()’. This method creates a wrapper around the original HashMap and locks it whenever a thread tries to access or modify it.
|
||||
|
||||
```java
|
||||
Collections.synchronizedMap(instanceOfHashMap);
|
||||
```
|
||||
|
||||
The `synchronizedMap()` is a static method of the Collections class that takes an instance of HashMap collection as a parameter and returns a synchronized Map from it. However,it is important to note that only the map itself is synchronized, not its views such as keyset and entrySet. Therefore, if we want to iterate over the synchronized map, we need to use a synchronized block or a lock to ensure exclusive access.
|
||||
|
||||
```java
|
||||
import java.util.*;
|
||||
public class Maps {
|
||||
public static void main(String[] args) {
|
||||
HashMap<String, Integer> cart = new HashMap<>();
|
||||
// Adding elements in the cart map
|
||||
cart.put("Butter", 5);
|
||||
cart.put("Milk", 10);
|
||||
cart.put("Rice", 20);
|
||||
cart.put("Bread", 2);
|
||||
cart.put("Peanut", 2);
|
||||
// printing synchronized map from HashMap
|
||||
Map mapSynched = Collections.synchronizedMap(cart);
|
||||
System.out.println("Synchronized Map from HashMap: " + mapSynched);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Hashtable vs Concurrent Hashmap**
|
||||
HashMap is generally suitable for single threaded applications and is faster than Hashtable, however in multithreading environments we have you use **Hashtable** or **Concurrent Hashmap**. So let us talk about them.
|
||||
|
||||
While both Hashtable and Concurrent Hashmap collections offer the advantage of thread safety, their underlying architectures and capabilities significantly differ. Whether we’re building a legacy system or working on modern, microservices-based cloud applications, understanding these nuances is critical for making the right choice.
|
||||
|
||||
Let's see the differences between Hashtable and ConcurrentHashMap, delving into their performance metrics, synchronization features, and various other aspects to help us make an informed decision.
|
||||
|
||||
**1. Hashtable**
|
||||
Hashtable is one of the oldest collection classes in Java and has been present since JDK 1.0. It provides key-value storage and retrieval APIs:
|
||||
|
||||
```java
|
||||
Hashtable<String, String> hashtable = new Hashtable<>();
|
||||
hashtable.put("Key1", "1");
|
||||
hashtable.put("Key2", "2");
|
||||
hashtable.putIfAbsent("Key3", "3");
|
||||
String value = hashtable.get("Key2");
|
||||
```
|
||||
**The primary selling point of Hashtable is thread safety, which is achieved through method-level synchronization**.
|
||||
|
||||
Methods like put(), putIfAbsent(), get(), and remove() are synchronized. Only one thread can execute any of these methods at a given time on a Hashtable instance, ensuring data consistency.
|
||||
|
||||
**2. Concurrent Hashmap**
|
||||
ConcurrentHashMap is a more modern alternative, introduced with the Java Collections Framework as part of Java 5.
|
||||
|
||||
Both Hashtable and ConcurrentHashMap implement the Map interface, which accounts for the similarity in method signatures:
|
||||
```java
|
||||
ConcurrentHashMap<String, String> concurrentHashMap = new ConcurrentHashMap<>();
|
||||
concurrentHashMap.put("Key1", "1");
|
||||
concurrentHashMap.put("Key2", "2");
|
||||
concurrentHashMap.putIfAbsent("Key3", "3");
|
||||
String value = concurrentHashMap.get("Key2");
|
||||
```
|
||||
|
||||
ConcurrentHashMap, on the other hand, provides thread safety with a higher level of concurrency. It allows multiple threads to read and perform limited writes simultaneously **without locking the entire data structure**. This is especially useful in applications that have more read operations than write operations.
|
||||
|
||||
**Performance Comparison**
|
||||
Hashtable locks the entire table during a write operation, thereby preventing other reads or writes. This could be a bottleneck in a high-concurrency environment.
|
||||
|
||||
ConcurrentHashMap, however, allows concurrent reads and limited concurrent writes, making it more scalable and often faster in practice.
|
||||
@@ -0,0 +1,136 @@
|
||||
# Functional Programming in Java
|
||||
---
|
||||
Functional Programming (FP) is a programming paradigm that treats computation as the evaluation of mathematical functions and avoids changing-state and mutable data. In Java, functional programming features were introduced in Java 8 with the addition of lambda expressions, the `java.util.function` package, and the Stream API. Here are the key concepts of Functional Programming in Java:
|
||||
- Lambda Expressions
|
||||
- Functional Interfaces
|
||||
- Stream API
|
||||
- Immutabilitity
|
||||
- Higher Order Functions
|
||||
- Parallelism
|
||||
|
||||
### 1. Lambda Expressions:
|
||||
Lambda expressions are a concise way to represent anonymous functions. They provide a clear and concise syntax for writing functional interfaces (interfaces with a single abstract method). Lambda expressions are the cornerstone of functional programming in Java.
|
||||
|
||||
```java
|
||||
// Traditional anonymous class
|
||||
Runnable runnable1 = new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("Hello, world!");
|
||||
}
|
||||
};
|
||||
|
||||
// Lambda expression
|
||||
Runnable runnable2 = () -> System.out.println("Hello, world!");
|
||||
```
|
||||
|
||||
### 2. Functional Interfaces:
|
||||
Functional interfaces are interfaces with a single abstract method, often referred to as functional methods. They can have multiple default or static methods, but they must have only one abstract method.
|
||||
```java
|
||||
@FunctionalInterface
|
||||
interface MyFunctionalInterface {
|
||||
void myMethod();
|
||||
}
|
||||
```
|
||||
Lambda expressions can be used to instantiate functional interfaces:
|
||||
```java
|
||||
MyFunctionalInterface myFunc = () -> System.out.println("My method implementation");
|
||||
```
|
||||
|
||||
In Java, the `java.util.function` package provides several functional interfaces that represent different types of functions. These functional interfaces are part of the functional programming support introduced in Java 8 and are commonly used with lambda expressions. Here's an explanation of some commonly used functional interfaces in Java:
|
||||
|
||||
##### Function<T, R>
|
||||
Represents a function that takes one argument of type T and produces a result of type R.
|
||||
The method `apply(T t)` is used to apply the function.
|
||||
```java
|
||||
Function<String, Integer> stringLengthFunction = s -> s.length();
|
||||
int length = stringLengthFunction.apply("Java");
|
||||
```
|
||||
|
||||
##### Consumer<T>
|
||||
Represents an operation that accepts a single input argument of type T and returns no result. The method `accept(T t)` is used to perform the operation.
|
||||
```java
|
||||
Consumer<String> printUpperCase = s -> System.out.println(s.toUpperCase());
|
||||
printUpperCase.accept("Java");
|
||||
```
|
||||
|
||||
##### BiFunction<T,U,R>
|
||||
Represents a function that takes two arguments of types T and U and produces a result of type R. The method `apply(T t, U u)` is used to apply the function.
|
||||
```java
|
||||
BiFunction<Integer, Integer, Integer> sumFunction = (a, b) -> a + b;
|
||||
int sum = sumFunction.apply(3, 5);
|
||||
```
|
||||
##### Predicate<T>
|
||||
Represents a predicate (boolean-valued function) that takes one argument of type T.
|
||||
The method `test(T t)` is used to test the predicate
|
||||
```java
|
||||
Predicate<Integer> isEven = n -> n % 2 == 0;
|
||||
boolean result = isEven.test(4); // true
|
||||
```
|
||||
##### Supplier<T>
|
||||
Represents a supplier of results.
|
||||
The method get() is used to get the result.
|
||||
```java
|
||||
Supplier<Double> randomNumberSupplier = () -> Math.random();
|
||||
double randomValue = randomNumberSupplier.get();
|
||||
```
|
||||
|
||||
These functional interfaces facilitate the use of lambda expressions and support the functional programming paradigm in Java. They can be used in various contexts, such as with the Stream API, to represent transformations, filters, and other operations on collections of data. The introduction of these functional interfaces in Java 8 enhances code readability and expressiveness.
|
||||
|
||||
### 3. Streams
|
||||
Streams provide a functional approach to processing sequences of elements. They allow you to express complex data manipulations using a pipeline of operations, such as map, filter, and reduce. Streams are part of the `java.util.stream` package.
|
||||
|
||||
```java
|
||||
List<String> strings = Arrays.asList("abc", "def", "ghi", "jkl");
|
||||
|
||||
// Filter strings starting with 'a' and concatenate them
|
||||
String result = strings.stream()
|
||||
.filter(s -> s.startsWith("a"))
|
||||
.map(String::toUpperCase)
|
||||
.collect(Collectors.joining(", "));
|
||||
|
||||
System.out.println(result); // Output: ABC
|
||||
```
|
||||
### 4. Immutablility
|
||||
Functional programming encourages immutability, where objects once created cannot be changed. In Java, you can use the final keyword to create immutable variables.
|
||||
|
||||
The immutability is a big thing in a multithreaded application. It allows a thread to act on an immutable object without worrying about the other threads because it knows that no one is modifying the object. So the immutable objects are more thread safe than the mutable objects. If you are into concurrent programming, you know that the immutability makes your life simple.
|
||||
|
||||
### 5. Higher-Order Functions:
|
||||
Functional programming supports higher-order functions, which are functions that can take other functions as parameters or return functions as results. Higher-order functions are a key concept in functional programming, enabling a more expressive and modular coding style. Java, starting from version 8, introduced support for higher-order functions with the introduction of lambda expressions and the `java.util.function` package.
|
||||
|
||||
|
||||
```java
|
||||
// Function that takes a function as a parameter
|
||||
public static void processNumbers(List<Integer> numbers, Function<Integer, Integer> processor) {
|
||||
for (int i = 0; i < numbers.size(); i++) {
|
||||
numbers.set(i, processor.apply(numbers.get(i)));
|
||||
}
|
||||
}
|
||||
|
||||
// Usage of higher-order function
|
||||
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
|
||||
processNumbers(numbers, x -> x * 2);
|
||||
System.out.println(numbers); // Output: [2, 4, 6, 8, 10]
|
||||
```
|
||||
|
||||
### 7. Parallelism:
|
||||
Functional programming encourages writing code that can easily be parallelized. The Stream API provides methods for parallel execution of operations on streams.
|
||||
```java
|
||||
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
|
||||
|
||||
// Parallel stream processing
|
||||
int sum = numbers.parallelStream()
|
||||
.mapToInt(Integer::intValue)
|
||||
.sum();
|
||||
System.out.println(sum); // Output: 15
|
||||
```
|
||||
---
|
||||
## Benefits of Functional Programming in Java
|
||||
- **Conciseness**: Lambda expressions make code more concise and readable.
|
||||
- **Parallelism**: Easier to parallelize code due to immutability and statelessness.
|
||||
- **Predictability**: Immutability reduces side effects and makes code more predictable.
|
||||
- **Testability**: Functions with no side effects are easier to test.
|
||||
- **Modularity**: Encourages modular and reusable code.
|
||||
|
||||
Functional programming in Java complements the existing object-oriented programming paradigm and provides developers with powerful tools to write more expressive, modular, and maintainable code. It promotes the use of pure functions, immutability, and higher-order functions, leading to code that is often more concise and easier to reason about.
|
||||
@@ -0,0 +1,276 @@
|
||||
|
||||
# Chapter - Garbage Collection in Java
|
||||
-----
|
||||
|
||||
|
||||
### Introduction
|
||||
|
||||
One of the reasons that make Java as a robust programming language is its memory management. Memory management can be a difficult, tedious task in traditional programming environments. For example, in C/C++, the programmer will often manually allocate and free dynamic memory. This sometimes leads to problems, because programmers will either forget to free memory that has been previously allocated or, worse, try to free some memory that another part of their code is still using. Java virtually eliminates these problems by managing memory allocation and deallocation for you. In fact, deallocation is completely automatic, because Java provides garbage collection for unused objects. In this tutorial, we will study the following topics.
|
||||
|
||||
**Part-I**
|
||||
- Java Memory Model (Stack and Heap)
|
||||
- Need for Garbage Collection (Operations, Benefits, Disadvantanges)
|
||||
- Benefits and Disadvantages of GC
|
||||
|
||||
**Part-II**
|
||||
- Memory Allocation, Defragmentation and Garbage Collection
|
||||
- Conditions for Garbage Collector to run
|
||||
- Garbage Collection for Java Objects
|
||||
- Handling unmanaged resources
|
||||
|
||||
**Part-III**
|
||||
- Choosing a Garbage Collection Algorithm
|
||||
- Understanding Mark and Sweep
|
||||
- Garbage Collectors in Java 17
|
||||
|
||||
### Java Memory Model - Stack vs Heap
|
||||
Applications need memory to run, because they need to create objects in the memory and perform computational tasks. These can be created on Stack and Heap Memory. Lets us quickly discuss the features of stack and heap memory.
|
||||
|
||||
Local primitive variables and reference variables to objects data types are created on stack memory and cleared automatically when the stack frame is popped after the function call gets over. Hence, everything associated when stack memory gets cleared off automatically following the LIFO order in the call stack. There is no garbage collection involved in stack memory. Because of simplicity in memory allocation (LIFO), stack memory is very fast when compared to heap memory.
|
||||
|
||||
```java
|
||||
func(){
|
||||
int a = 10; //here 'a' is created on stack
|
||||
int arr[] = new int[10];
|
||||
// here arr reference is created on stack but actual allocation is on heap
|
||||
...
|
||||
}
|
||||
```
|
||||
However, you need heap memory when you need to allocate any kind of objects like arrays, user defined objects, dynamic data structures such as arraylist, strings, trees etc
|
||||
|
||||
Whenever an object is created, it’s always stored in the Heap space and stack memory contains the reference to it. Objects stored in the heap are globally accessible whereas stack memory can’t be accessed by other threads. Creating objects on heap also allows passing large objects by reference across different functions, thus avoiding the need to create a copy of the object. For such objects on heap de-allocation is required for unused objects, which can be performed explicitly by invoking `delete` in langages like C++. But language like Java, Python provide support for automatic garbage collection.
|
||||
|
||||
When stack memory is full, Java runtime throws `java.lang.StackOverFlowError` whereas if heap memory is full, it throws `java.lang.OutOfMemoryError: Java Heap Space error`. Stack memory size is very less when compared to Heap memory. We can use `-Xms` and `-Xmx` JVM option to define the startup size and maximum size of heap memory. We can use `-Xss` to define the stack memory size.
|
||||
|
||||
|
||||
### Need for Garbage Collection
|
||||
|
||||
The garbage collector manages the allocation and release of memory for an application. Therefore, developers working with managed code don't have to write code to perform memory management tasks. Automatic memory management can eliminate common problems such as forgetting to free an object and causing a memory leak or attempting to access freed memory for an object that's already been freed.
|
||||
|
||||
**Operations performed by a Garbage Collector**
|
||||
- Allocates from and gives back memory to the operating system.
|
||||
- Hands out that memory to the application as it requests it.
|
||||
- Determines which parts of that memory is still in use by the application.
|
||||
- Reclaims the unused memory for reuse by the application.
|
||||
- Running memory defragmentation.
|
||||
|
||||
**Benefits of Garbage Collector**
|
||||
- Frees developers from having to manually release memory.
|
||||
- Allocates objects on the managed heap efficiently.
|
||||
- Reclaims objects that are no longer being used, clears their memory, and keeps the memory available for future allocations.
|
||||
- Provides memory safety by making sure that an object can't use for itself the memory allocated for another object.
|
||||
- No overhead of handling Dangling Pointer
|
||||
|
||||
**Disadvantages of Garbage Collector**
|
||||
- Java garbage collection helps your Java environments and applications perform more efficiently. However, you can still potentially run into issues with automatic garbage collection, including degraded application performance.
|
||||
- Since JVM has to keep track of object reference creation/deletion, this activity requires more CPU power than the original application. It may affect the performance of requests which require large memory.
|
||||
- Programmers have no control over the scheduling of CPU time dedicated to freeing objects that are no longer needed.
|
||||
- Using some GC implementations might result in the application stopping unpredictably.
|
||||
|
||||
|
||||
While you can’t manually override automatic garbage collection, there are things you can do to optimize garbage collection in your application environment, such as changing the garbage collector you use, removing all references to unused Java objects, tuning the parameters of Garbage collector etc.
|
||||
|
||||
**Memory Allocation, Defragmentation & Garbage Collection**
|
||||
We’ve seen how heap memory can provide a flexible way of allocation chunks of memory on-the-go. The chunks aren’t planned ahead of time; it’s a real-time thing: when the program, for whatever reason, needs more memory, then the operating system finds an available chunk and allocates that chunk to the program.The program can use it until it’s done with that chunk, at which time it releases the chunk for later use by the same or a different program.
|
||||
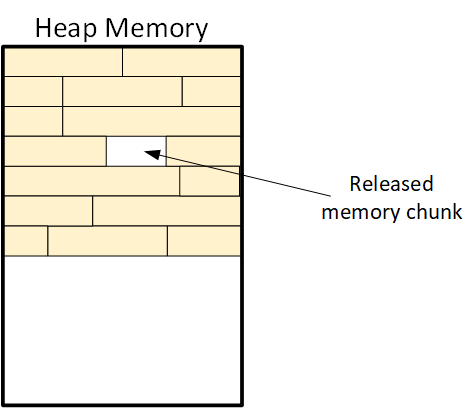
|
||||
|
||||
After some time, the memory might look like this.
|
||||
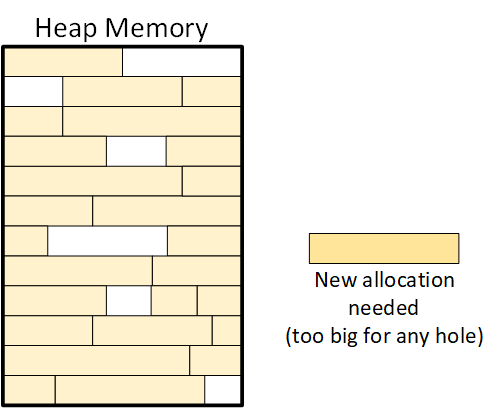
|
||||
|
||||
Now what? There’s enough free memory for the new allocation, but the problem is that it’s all broken up all over the place. Said another way, it’s fragmented. We really don’t want to break up the allocation and spread it over multiple holes. That would use more memory (for managing where all the pieces are), and it would slow things down.
|
||||
|
||||
So we’re left with the problem: how do we allocate that new chunk? We first need to reorganize the memory and move things around to get all of those holes together into a larger chunk of available memory. That means closing up the holes and “pushing” the holes to the end of the memory where they can be reused.
|
||||
|
||||
That process of moving things around to bring the free memory chunks together is called **defragmentation**.The process of defragmenting memory by moving multiple free “holes” in memory together so that they can be allocated more effectively.And yeah, it takes some time to do. It’s also hard to predict when it will be needed, since it all depends on who needs memory and releases memory at what time. The process is fast enough to where you may not notice it, but it can make a difference.
|
||||
|
||||
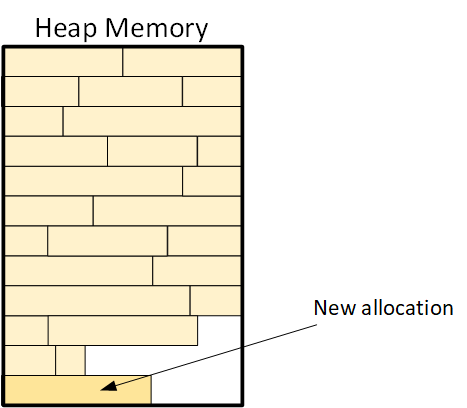
|
||||
|
||||
**Pseudocode for New()**
|
||||
```java
|
||||
def new():
|
||||
obj = allocate() //request for memory
|
||||
if obj == NULL:
|
||||
GC.collect() //trigger garbage collector
|
||||
obj = allocate() //re-try to allocate memory
|
||||
if obj == NULL: //no garbage was collected or not sufficient memory
|
||||
raise OutOfMemoryError
|
||||
|
||||
return obj
|
||||
```
|
||||
|
||||
**Important Note**
|
||||
Garbage collection only occurs sporadically (if at all) during the execution of your program. It will not occur simply because one or more objects exist that are no longer used. Furthermore, different Java run-time implementations will take varying approaches to garbage collection, but for the most developers, you should not have to think about it while writing your programs. The classes in the **java.lang.ref** package provide more flexible control over the garbage collection process.
|
||||
|
||||
There are various ways in which the references to an object can be released to make it a candidate for Garbage Collection. Some of them are:
|
||||
|
||||
**By making a reference null**
|
||||
```java
|
||||
Student student = new Student();
|
||||
student = null;
|
||||
```
|
||||
|
||||
**By assigning a reference to another**
|
||||
```java
|
||||
Student studentOne = new Student();
|
||||
Student studentTwo = new Student();
|
||||
studentOne = studentTwo;
|
||||
```
|
||||
**Conditions for a Garbage Collector to run**
|
||||
Garbage collection occurs when one of the following conditions is true:
|
||||
|
||||
- The system has low physical memory. The memory size is detected by either the low memory notification from the operating system or low memory as indicated by the host.
|
||||
|
||||
- The memory that's used by allocated objects on the managed heap surpasses an acceptable threshold. This threshold is continuously adjusted as the process runs.
|
||||
|
||||
- The GC.Collect() method is called. In almost all cases, you don't have to call this method because the garbage collector runs continuously. This method is primarily used for unique situations and testing.
|
||||
|
||||
**Handling unmanaged resources and finalize() Method**
|
||||
For most of the objects your application creates, you can rely on garbage collection to perform the necessary memory management tasks automatically. However, unmanaged resources require explicit cleanup. The most common type of unmanaged resource is an object that wraps an operating system resource, such as a file handle, window handle, or network connection. Although the garbage collector can track the lifetime of a managed object that encapsulates an unmanaged resource, it doesn't have specific knowledge about how to clean up the resource. finalize() method in Java is a method of the Object class that is used to perform cleanup activity before destroying any object. It is called by Garbage collector before destroying the objects from memory. You can either use a safe handle to wrap the unmanaged resource, or override the Object.Finalize() method. `finalize()` method is called by default for every object before its deletion. This method helps Garbage Collector to close all the resources used by the object and helps JVM in-memory optimization.
|
||||
|
||||
-----
|
||||
### Choice of a Garbage Collector Algorithm
|
||||
|
||||
Any garbage collection algorithm must perform 2 basic operations. One, it should be able to detect all the unreachable objects and secondly, it must reclaim the heap space used by the garbage objects and make the space available again to the program.
|
||||
|
||||
When does the choice of a garbage collector matter? For some applications, the answer is never. That is, the application can perform well in the presence of garbage collection with pauses of modest frequency and duration. However, this isn't the case for a large class of applications, particularly those with large amounts of data (multiple gigabytes), many threads, and high transaction rates. Garbage collectors make assumptions about the way applications use objects, and these are reflected in tunable parameters that can be adjusted for improved performance.
|
||||
|
||||
|
||||
Here are few desirable properties of a Garbage Collector.
|
||||
|
||||
##### 1. Safety
|
||||
A garbage collector is safe when it never reclaims the space of a LIVE object and always cleans up only the dead objects.
|
||||
Although this looks like an obvious requirement, some GC algorithms claim space of LIVE objects just to gain that extra ounce of performance.
|
||||
|
||||
##### 2.Throughput
|
||||
A garbage collector should be as little time cleaning up the garbage as possible; this way it would ensure that the CPU is spent on doing actual work and not just cleaning up the mess.
|
||||
Most garbage collectors hence run small cycles frequently and a major cycle does deep cleaning once a while. This way they maximize the overall throughput and ensure we spend more time doing actual work.
|
||||
|
||||
|
||||
##### 3.Completeness
|
||||
A garbage collector is said to be complete when it eventually reclaims all the garbage from the heap.
|
||||
It is not desirable to do a complete clean-up every time the GC is executed, but eventually, a GC should guarantee that the garbage is cleaned up ensuring zero memory leaks.
|
||||
|
||||
##### 4.Pause Time
|
||||
Some garbage collectors pause the program execution during the cleanup and this induces a "pause". Long pauses affect the throughput of the system and may lead to unpredictable outcomes; so a GC is designed and tuned to minimize the pause time.
|
||||
The garbage collector needs to pause the execution because it needs to either run defragmentation where the heap objects are shuffled freeing up larger contiguous memory segments.
|
||||
|
||||
|
||||
##### 5.Space overhead
|
||||
Garbage collectors require auxiliary data structures to track objects efficiently and the memory required to do so is pure overhead. An efficient GC should have this space overhead as low as possible allowing sufficient memory for the program execution.
|
||||
|
||||
|
||||
##### 6.Language Specific Optimizations
|
||||
Most GC algorithms are generic but when bundled with the programing language the GC can exploit the language patterns and object allocation nuances. So, it is important to pick the GC that can leverage these details and make its execution as efficient as possible.
|
||||
For example, in some programming languages, GC runs in constant time by exploiting how objects are allocated on the heap.
|
||||
|
||||
##### 7.Scalability
|
||||
Most GC are efficient in cleaning up a small chunk of memory, but a scalable GC would run efficiently even on a server with large RAM. Similarly, a GC should be able to leverage multiple CPU cores, if available, to speed up the execution.
|
||||
|
||||
|
||||
Amdahl's law (parallel speedup in a given problem is limited by the sequential portion of the problem) implies that most workloads can't be perfectly parallelized; some portion is always sequential and doesn't benefit from parallelism. In the Java platform, there are currently four supported garbage collection alternatives and all but one of them, the serial GC, parallelize the work to improve performance. It's very important to keep the overhead of doing garbage collection as low as possible.
|
||||
|
||||
# Garbage Collection Algorithm
|
||||
|
||||
A theoretical, most straightforward garbage collection algorithm iterates over every reachable object every time it runs. Any leftover objects are considered garbage. The time this approach takes is proportional to the number of live objects, which is prohibitive for large applications maintaining lots of live data.
|
||||
|
||||
|
||||
## Mark-and-sweep Algorithm
|
||||
Over the lifetime of a Java application, new objects are created and released. Eventually, some objects are no longer needed. You can say that at any point in time, the heap memory consists of two types of objects:
|
||||
|
||||
- Live - these objects are being used and referenced from somewhere else
|
||||
|
||||
- Dead - these objects are no longer used or referenced from anywhere and can be deleted.
|
||||
|
||||
|
||||
The Java garbage collection process uses a mark-and-sweep algorithm. Here’s how that works
|
||||
There are two phases in this algorithm: *mark followed by sweep*.
|
||||
|
||||
- During the mark phase, the garbage collector traverses object trees starting at their roots. When an object is reachable from the root, the mark bit is set to 1 (true). Meanwhile, the mark bits for unreachable objects is unchanged (false).
|
||||
|
||||
|
||||
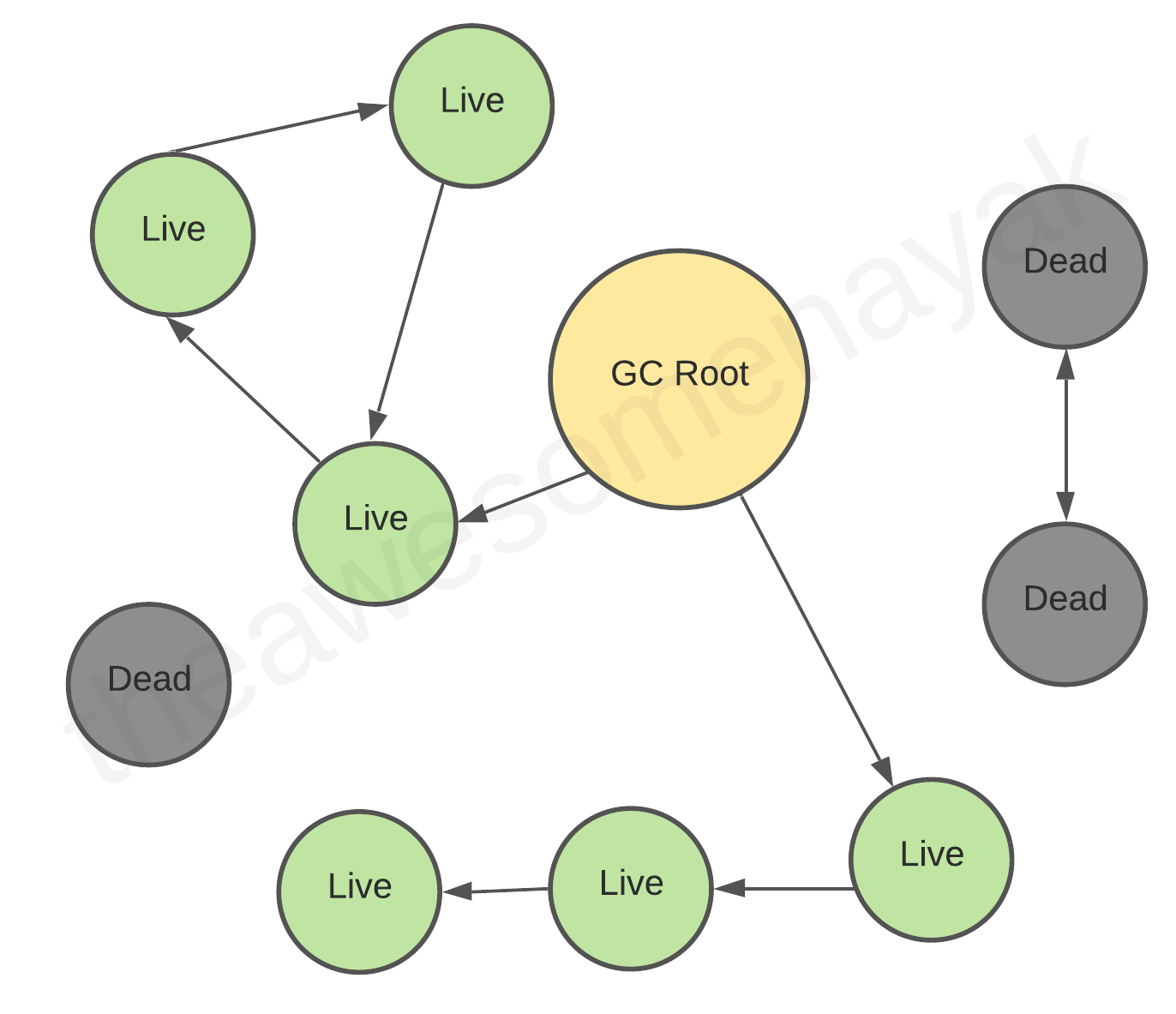
|
||||
|
||||
|
||||
- During the sweep phase, the garbage collector traverses the heap, reclaiming memory from all items with a mark bit of 0 (false).
|
||||
|
||||
**What are Garbage Collection Roots?**
|
||||
Garbage collectors work on the concept of Garbage Collection Roots (GC Roots) to identify live and dead objects. The garbage collector traverses the whole object graph in memory, starting from those Garbage Collection Roots and following references from the roots to other objects.
|
||||
|
||||
*Object graph* is basically a dependency graph between objects.In this graph, the nodes are Java objects, and the edges are the explicit or implied references that allow a running program to "reach" other objects from a given one. It is used to determine which objects are reachable and which not, so that all unreachable objects could be made eligible for garbage collection.
|
||||
|
||||
----
|
||||
#### Garbage Collectors in Java 17
|
||||
Java 17 supports several types of garbage collectors, including the Serial GC, Parallel GC, Concurrent Mark Sweep (CMS) GC, G1 GC, and the newly-introduced Z Garbage Collector (ZGC) and Shenandoah GC. Each of these garbage collectors has unique characteristics and can be chosen based on the requirements of your Java application. The Java garbage collectors employ various techniques to improve the efficiency of these operations:
|
||||
|
||||
- Java Garbage Collectors implement a generational garbage collection strategy that categorizes objects by age. Having to mark and compact all the objects in a JVM is inefficient. As more and more objects are allocated, the list of objects grows, leading to longer garbage collection times.
|
||||

|
||||
|
||||
- Use multiple threads to aggressively make operations parallel, or perform some long-running operations in the background concurrent to the application.
|
||||
|
||||
- Try to recover larger contiguous free memory by compacting live objects.
|
||||
|
||||
|
||||
**1. Serial Garbage Collector**
|
||||
|
||||
The Serial GC, also known as the ‘single-threaded’ GC, is the simplest form of garbage collection in Java. It uses just one CPU thread for garbage collection, which means it can be efficient for applications with a small heap size (up to approximately 100MB). However, during the garbage collection process, user threads are paused, which can lead to latency issues in larger applications. All garbage collection events are conducted serially in one thread. Compaction is executed after each garbage collection.
|
||||
|
||||

|
||||
|
||||
|
||||
Compacting describes the act of moving objects in a way that there are no holes between objects. After a garbage collection sweep, there may be holes left between live objects. Compacting moves objects so that there are no remaining holes.
|
||||
To enable Serial Garbage Collector, we can use the following argument:
|
||||
|
||||
```java -XX:+UseSerialGC -jar Application.java```
|
||||
|
||||
**2. Parallel Garbage Collector**
|
||||
Unlike Serial Garbage Collector, it uses multiple threads for managing heap space, but it also freezes other application threads while performing GC. The parallel collector is intended for applications with medium-sized to large-sized data sets that are run on multiprocessor or multithreaded hardware. This is the default implementation of GC in the JVM and is also known as Throughput Collector. Running the Parallel GC also causes a "stop the world event" and the application freezes. Since it is more suitable in a multi-threaded environment, it can be used when a lot of work needs to be done and long pauses are acceptable, for example running a batch job.
|
||||
|
||||
Multiple threads are used for minor garbage collection in the Young Generation. A single thread is used for major garbage collection in the Old Generation.
|
||||
If we use this GC, we can specify maximum garbage collection threads and pause time, throughput, and footprint (heap size) using command line arguments.
|
||||
|
||||
```java -XX:+UseParallelGC -jar Application.java```
|
||||
|
||||

|
||||
|
||||
**3. Concurrent Mark and Sweep**
|
||||
This is also known as the concurrent low pause collector. Multiple threads are used for minor garbage collection using the same algorithm as Parallel. Major garbage collection is multi-threaded, like Parallel Old GC, but CMS runs concurrently alongside application processes to minimize “stop the world” events. Because of this, the CMS collector uses more CPU than other GCs. If you can allocate more CPU for better performance, then the CMS garbage collector is a better choice than the parallel collector. No compaction is performed in CMS GC.
|
||||
|
||||

|
||||
|
||||
|
||||
The JVM argument to use Concurrent Mark Sweep Garbage Collector is ```java -XX:+UseConcMarkSweepGC```
|
||||
|
||||
**4. G1 Garbage Collector**
|
||||
G1 (Garbage First) Garbage Collector is designed for applications running on multi-processor machines with large memory space. It’s available from the JDK7 Update 4 and in later releases.
|
||||
|
||||
When performing garbage collections, G1 shows a concurrent global marking phase (i.e. phase 1, known as Marking) to determine the liveness of objects throughout the heap.
|
||||
|
||||
After the mark phase is complete, G1 knows which regions are mostly empty. It collects in these areas first, which usually yields a significant amount of free space (i.e. phase 2, known as Sweeping).
|
||||
|
||||
```java -XX:+UseG1GC -jar Application.java```
|
||||
|
||||
|
||||
**5. Z Garbage Collector**
|
||||
The Z Garbage Collector (ZGC) is a scalable low latency garbage collector. ZGC performs all expensive work concurrently, without stopping the execution of application threads for more than 10ms, which makes is suitable for applications which require low latency and/or use a very large heap (multi-terabytes).
|
||||
The Z Garbage Collector is available as an experimental feature, and is enabled with the command-line options
|
||||
```java -XX:+UnlockExperimentalVMOptions -XX:+UseZGC```
|
||||
|
||||
#### Conclusion
|
||||
Remember, there’s no one-size-fits-all when it comes to choosing a garbage collector. A GC that works great for one application might not be the best choice for another. As with most aspects of system tuning, the best strategy often involves a mix of knowledge, experimentation, and a thorough understanding of your specific use case.
|
||||
|
||||
If your application doesn't have strict pause-time requirements, you should just run your application and allow the JVM to select the right collector.
|
||||
|
||||
Most of the time, the default settings should work just fine. If necessary, you can adjust the heap size to improve performance. If the performance still doesn't meet your goals, you can modify the collector as per your application requirements:
|
||||
|
||||
**Serial** - If the application has a small data set (up to approximately 100 MB) and/or it will be run on a single processor with no pause-time requirements
|
||||
|
||||
**Parallel** - If peak application performance is the priority and there are no pause-time requirements or pauses of one second or longer are acceptable
|
||||
|
||||
**CMS/G1** - If response time is more important than overall throughput and garbage collection pauses must be kept shorter than approximately one second
|
||||
|
||||
**ZGC** - If response time is a high priority, and/or you are using a very large heap
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -0,0 +1,248 @@
|
||||
## Java Collections - Hashmap, Linked Hashmap & Tree Map
|
||||
|
||||
- Hashmap
|
||||
- Linked Hashmap
|
||||
- TreeMap
|
||||
|
||||
|
||||
A **hash map** is good as a general-purpose map implementation that provides rapid storage and retrieval operations. However, it falls short because of its chaotic and unorderly arrangement of entries.
|
||||
|
||||
A **linked hash map** possesses the good attributes of hash maps and adds order to the entries. It performs better where there is a lot of iteration because only the number of entries is taken into account regardless of capacity.
|
||||
|
||||
A **tree map** takes ordering to the next level by providing complete control over how the keys should be sorted. On the flip side, it offers worse general performance than the other two alternatives.
|
||||
|
||||
### 1. Hashmap
|
||||
Let’s first look at what it means that HashMap is a map. A map is a key-value mapping, which means that every key is mapped to exactly one value and that we can use the key to retrieve the corresponding value from a map.
|
||||
|
||||
The advantage of a HashMap is that the time complexity to insert and retrieve a value is O(1) on average. We have covered the internal workings in the video lectures already.
|
||||
Before we proceed Let’s summarize how the put and get operations work.
|
||||
|
||||
**Put()**
|
||||
When we add an element to the map, HashMap calculates the bucket. If the bucket already contains a value, the value is added to the list (or tree) belonging to that bucket. If the load factor becomes bigger than the maximum load factor of the map, the capacity is doubled.
|
||||
|
||||
**Get()**
|
||||
When we want to get a value from the map, HashMap calculates the bucket and gets the value with the same key from the list (or tree).
|
||||
|
||||
**Example Code**
|
||||
Lets try to create a hashmap of products. We will create a Product class first.
|
||||
```java
|
||||
public class Product {
|
||||
|
||||
private String name;
|
||||
private String description;
|
||||
private List<String> tags;
|
||||
|
||||
// standard getters/setters/constructors
|
||||
|
||||
public Product addTagsOfOtherProduct(Product product) {
|
||||
this.tags.addAll(product.getTags());
|
||||
return this;
|
||||
}
|
||||
}
|
||||
```
|
||||
We can now create a HashMap with the key of type String and elements of type Product:
|
||||
|
||||
```java
|
||||
Map<String, Product> productsByName = new HashMap<>();
|
||||
```
|
||||
**1. Put Method**
|
||||
Adding to hashmap.
|
||||
```java
|
||||
Product eBike = new Product("E-Bike", "A bike with a battery");
|
||||
Product roadBike = new Product("Road bike", "A bike for competition");
|
||||
//using the Put Method
|
||||
productsByName.put(eBike.getName(), eBike);
|
||||
productsByName.put(roadBike.getName(), roadBike);
|
||||
```
|
||||
|
||||
**2. Get Method**
|
||||
We can retrieve a value from the map by its key:
|
||||
```java
|
||||
Product nextPurchase = productsByName.get("E-Bike");
|
||||
assertEquals("A bike with a battery", nextPurchase.getDescription());
|
||||
```
|
||||
|
||||
If we try to find a value for a key that doesn’t exist in the map, we’ll get a null value:
|
||||
|
||||
**3. Remove**
|
||||
|
||||
We can remove a key-value mapping from the HashMap:
|
||||
```java
|
||||
productsByName.remove("E-Bike");
|
||||
assertNull(productsByName.get("E-Bike"));
|
||||
```
|
||||
|
||||
**4. Contains Key**
|
||||
To check if a key is present in the map, we can use the containsKey() method:
|
||||
```java
|
||||
productsByName.containsKey("E-Bike");
|
||||
```
|
||||
|
||||
-----
|
||||
**Hashmap with Custom Key Class**
|
||||
We can use any class as the key in our HashMap. However, for the map to work properly, we need to provide an implementation for equals() and hashCode().
|
||||
In most cases, we should use **immutable keys**. Or at least, we must be aware of the consequences of using mutable keys. If key changes after insertion, HashMap will be searching in the wrong bucket and leading to inconsistent behaviour.
|
||||
|
||||
|
||||
Let’s say we want to have a map with the product as the key and the price as the value:
|
||||
|
||||
```java
|
||||
HashMap<Product, Integer> priceByProduct = new HashMap<>();
|
||||
priceByProduct.put(eBike, 900);
|
||||
```
|
||||
Let’s implement the equals() and hashCode() methods:
|
||||
|
||||
|
||||
```java
|
||||
//Override these methods in the Product Class
|
||||
@Override
|
||||
public boolean equals(Object o) {
|
||||
if (this == o) {
|
||||
return true;
|
||||
}
|
||||
if (o == null || getClass() != o.getClass()) {
|
||||
return false;
|
||||
}
|
||||
|
||||
Product product = (Product) o;
|
||||
return Objects.equals(name, product.name) &&
|
||||
Objects.equals(description, product.description);
|
||||
}
|
||||
|
||||
@Override
|
||||
public int hashCode() {
|
||||
return Objects.hash(name, description);
|
||||
}
|
||||
```
|
||||
Note that `hashCode()` and `equals()` need to be overridden only for classes that we want to use as map keys, not for classes that are only used as values in a map.
|
||||
|
||||
-----
|
||||
|
||||
### 2. Linked Hashmap
|
||||
The LinkedHashMap class is very similar to HashMap in most aspects. However, the linked hash map is based on both hash table and linked list to enhance the functionality of hash map.
|
||||
|
||||
It maintains a doubly-linked list running through all its entries in addition to an underlying array of default size 16.
|
||||
|
||||
This linked list defines the order of iteration, which by default is the order of insertion of elements (insertion-order).
|
||||
|
||||
Let’s have a look at a linked hash map instance which orders its entries according to how they’re inserted into the map. It also guarantees that this order will be maintained throughout the life cycle of the map:
|
||||
|
||||
```java
|
||||
public void givenLinkedHashMap_whenGetsOrderedKeyset_thenCorrect() {
|
||||
LinkedHashMap<Integer, String> map = new LinkedHashMap<>();
|
||||
map.put(1, null);
|
||||
map.put(2, null);
|
||||
map.put(3, null);
|
||||
map.put(4, null);
|
||||
map.put(5, null);
|
||||
|
||||
Set<Integer> keys = map.keySet();
|
||||
Integer[] arr = keys.toArray(new Integer[0]);
|
||||
|
||||
for (int i = 0; i < arr.length; i++) {
|
||||
assertEquals(new Integer(i + 1), arr[i]);
|
||||
}
|
||||
}
|
||||
```
|
||||
We can guarantee that this test will always pass as the insertion order will always be maintained. We cannot make the same guarantee for a HashMap.
|
||||
|
||||
**Access Order Linked Hashmap**
|
||||
LinkedHashMap provides a special constructor which enables us to specify, among custom load factor (LF) and initial capacity, a different ordering mechanism/strategy called access-order:
|
||||
```java
|
||||
LinkedHashMap<Integer, String> map = new LinkedHashMap<>(16, .75f, true);
|
||||
```
|
||||
The first parameter is the initial capacity, followed by the load factor and the last param is the ordering mode. So, by passing in true, we turned on access-order, whereas the default was insertion-order.
|
||||
|
||||
This mechanism ensures that the order of iteration of elements is the order in which the elements were last accessed, from least-recently accessed to most-recently accessed.
|
||||
|
||||
**LRU using LinkedHashmap**
|
||||
And so, building a Least Recently Used (LRU) cache is quite easy and practical with this kind of map. A successful put or get operation results in an access for the entry:
|
||||
```java
|
||||
public void givenLinkedHashMap_whenAccessOrderWorks_thenCorrect() {
|
||||
LinkedHashMap<Integer, String> map
|
||||
= new LinkedHashMap<>(16, .75f, true);
|
||||
map.put(1, null);
|
||||
map.put(2, null);
|
||||
map.put(3, null);
|
||||
map.put(4, null);
|
||||
map.put(5, null);
|
||||
|
||||
Set<Integer> keys = map.keySet();
|
||||
assertEquals("[1, 2, 3, 4, 5]", keys.toString());
|
||||
|
||||
map.get(4);
|
||||
assertEquals("[1, 2, 3, 5, 4]", keys.toString());
|
||||
|
||||
map.get(1);
|
||||
assertEquals("[2, 3, 5, 4, 1]", keys.toString());
|
||||
|
||||
map.get(3);
|
||||
assertEquals("[2, 5, 4, 1, 3]", keys.toString());
|
||||
}
|
||||
|
||||
```
|
||||
Just like HashMap, LinkedHashMap implementation is not synchronized. So if you are going to access it from multiple threads and at least one of these threads is likely to change it structurally, then it must be externally synchronized.
|
||||
```java
|
||||
Map m = Collections.synchronizedMap(new LinkedHashMap());
|
||||
```
|
||||
We will learn more about concurrency in a separate tutorial.
|
||||
|
||||
-----
|
||||
### 3. TreeMap ###
|
||||
TreeMap is a map implementation that keeps its entries sorted according to the natural ordering of its keys or better still using a comparator if provided by the user at construction time.
|
||||
|
||||
By default, TreeMap sorts all its entries according to their natural ordering. For an integer, this would mean ascending order and for strings, alphabetical order.A hash map does not guarantee the order of keys stored and specifically does not guarantee that this order will remain the same over time, but a tree map guarantees that the keys will always be sorted according to the specified order.
|
||||
|
||||
|
||||
TreeMap, unlike a hash map and linked hash map, does not employ the hashing principle anywhere since it does not use an array to store its entries but uses a self-balanancing tree such as **Red Black Tree** data structure to store the entries.
|
||||
A red-black tree is a self-balancing binary search tree. This attribute and the above guarantee that basic operations like search, get, put and remove take logarithmic time O(log n) as For every insertion and deletion, the maximum height of the tree on any edge is maintained at O(log n) i.e. the tree balances itself continuously.
|
||||
|
||||
Just like hash map and linked hash map, a tree map is not synchronized and therefore the rules for using it in a multi-threaded environment are similar to those in the other two map implementations.
|
||||
|
||||
|
||||
A Tree Map example with Comparator
|
||||
```java
|
||||
public void givenTreeMap_whenOrdersEntriesByComparator_thenCorrect() {
|
||||
TreeMap<Integer, String> map =
|
||||
new TreeMap<>(Comparator.reverseOrder());
|
||||
map.put(3, "val");
|
||||
map.put(2, "val");
|
||||
map.put(1, "val");
|
||||
map.put(5, "val");
|
||||
map.put(4, "val");
|
||||
|
||||
assertEquals("[5, 4, 3, 2, 1]", map.keySet().toString());
|
||||
}
|
||||
```
|
||||
Notice that we placed the integer keys in a non-orderly manner but on retrieving the key set, we confirm that they are indeed maintained in ascending order. This is the natural ordering of integers.
|
||||
|
||||
We now know that TreeMap stores all its entries in sorted order. Because of this attribute of tree maps, we can perform queries like; find “largest”, find “smallest”, find all keys less than or greater than a certain value, etc.
|
||||
```java
|
||||
public void givenTreeMap_whenPerformsQueries_thenCorrect() {
|
||||
TreeMap<Integer, String> map = new TreeMap<>();
|
||||
map.put(3, "val");
|
||||
map.put(2, "val");
|
||||
map.put(1, "val");
|
||||
map.put(5, "val");
|
||||
map.put(4, "val");
|
||||
|
||||
Integer highestKey = map.lastKey();
|
||||
Integer lowestKey = map.firstKey();
|
||||
Set<Integer> keysLessThan3 = map.headMap(3).keySet();
|
||||
Set<Integer> keysGreaterThanEqTo3 = map.tailMap(3).keySet();
|
||||
|
||||
assertEquals(new Integer(5), highestKey);
|
||||
assertEquals(new Integer(1), lowestKey);
|
||||
assertEquals("[1, 2]", keysLessThan3.toString());
|
||||
assertEquals("[3, 4, 5]", keysGreaterThanEqTo3.toString());
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -0,0 +1,101 @@
|
||||
## Java Architecture
|
||||
|
||||
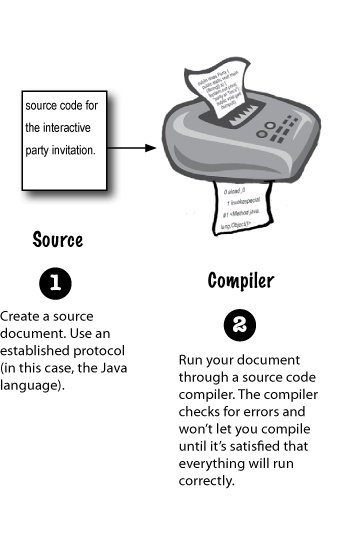
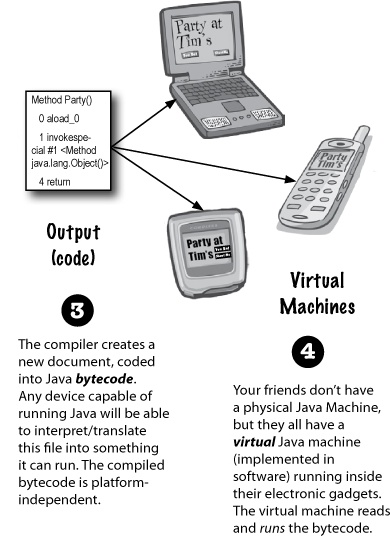
Java is a platform-independent language. For that we need to understand the steps of compilation and execution of code.
|
||||
|
||||
- The code written in Java, is converted into byte codes which is done by the Java Compiler
|
||||
- The byte code, is converted into machine code by the JVM.
|
||||
- The Machine code is executed directly by the machine.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Bytecodes are effectively *platform-independent*. The java virtual machine takes care of the differences between the bytecodes for the different platforms. This makes the Java Compiled Code platform independent.
|
||||
|
||||

|
||||
|
||||
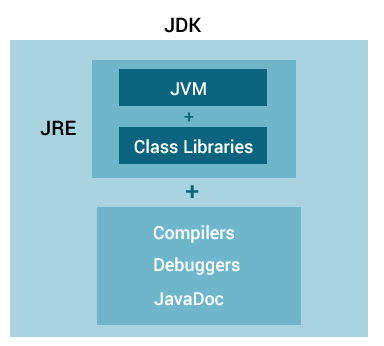
There are three main components of Java architechure: JVM, JRE, and JDK.
|
||||
Java Virtual Machine, Java Runtime Environment and Java Development Kit respectively. Lets understand them one by one.
|
||||
|
||||
# JVM
|
||||
JVM (Java Virtual Machine) is an abstract machine(software) that enables your computer to run a Java program.
|
||||
|
||||
When you run the Java program, Java compiler -`javac` first compiles your Java code to bytecode. Then, the JVM translates bytecode into native machine code (set of instructions that a computer's CPU executes directly). JVM comes with **JIT(Just-in-Time) compiler** that converts Java source code into low-level machine language. Hence, it runs more faster as a regular application.
|
||||
|
||||
|
||||
# JRE
|
||||
JRE (Java Runtime Environment) is a software package that provides Java class libraries, Java Virtual Machine (JVM), and other components that are required to run Java applications. JRE is the superset of JVM.
|
||||
|
||||
When our software tends to execute a particular program, it requires some environment to run in. Usually, it’s any operating system for example, Unix, Linux, Microsoft Windows, or the MacOS. Here our JRE acts as a translater and also a facilitator between the java program and the operating system.
|
||||
|
||||

|
||||
|
||||
### JDK
|
||||
JDK (Java Development Kit) is a software development kit required to develop applications in Java. When you download JDK, JRE is also downloaded with it.
|
||||
|
||||
In addition to JRE, JDK also contains a number of development tools (compilers, JavaDocs, Java Debugger, etc).
|
||||
|
||||
|
||||
|
||||
----
|
||||
### JVM Deep Dive
|
||||
Java applications are platform independent - write once, run anywhere. This is because of JVM which performs the following tasks -
|
||||
- Loads the code
|
||||
- Verifies the code
|
||||
- Executes the code
|
||||
- Provides runtime environment
|
||||
|
||||
Here are the important components of JVM architecture:
|
||||
|
||||
**1. Class Loader**
|
||||
The class loader is a subsystem used for loading class files. It performs three major functions viz. Loading, Linking, and Initialization.Whenever we run the java program, class loader loads it first.
|
||||
|
||||
**2. Method Area**
|
||||
It is one of the Data Area in JVM, in which Class data will be stored. Static Variables, Static Blocks, Static Methods, Instance Methods are stored in this area.
|
||||
JVM Method Area stores structure of class like metadata, the code for Java methods, and the constant runtime pool.
|
||||
|
||||
**3. Heap**
|
||||
A heap is created when the JVM starts up. It may increase or decrease in size while the application runs. All the Objects, arrays, and instance variables are stored in a heap. This memory is shared across multiple threads.
|
||||
|
||||
**4. JVM language Stacks**
|
||||
Java language Stacks store local variables, and its partial results. Each and every thread has its own JVM language stack, created concurrently as the thread is created. A new stack frame is created when method is invoked, and it is removed when method invocation process is complete. JVM stack is known as a thread stack.
|
||||
|
||||
|
||||
**5. PC Registers**
|
||||
PC registers store the address of the Java virtual machine instruction, which is currently executing. In Java, each thread has its separate PC register.
|
||||
|
||||
**6. Native Method Stacks**
|
||||
|
||||
Native method stacks hold the instruction of native code depends on the native library. It allocates memory on native heaps or uses any type of stack.
|
||||
|
||||
**7) Execution Engine**
|
||||
Execution Engine is the brain of JVM. It has two components.
|
||||
- JIT compiler
|
||||
- Garbage collector
|
||||
|
||||
**JIT compiler**: The Just-In-Time (JIT) compiler is a part of the runtime environment. It helps in improving the performance of Java applications by compiling bytecodes to machine code at run time. The JIT compiler is enabled by default. When a method is compiled, the JVM calls the compiled code of that method directly. The JIT compiler compiles the bytecode of that method into machine code, compiling it “just in time” to run.
|
||||
|
||||
**Garbage collector**: As the name explains that Garbage Collector means to collect the unused material. Well, in JVM this work is done by Garbage collection. It tracks each and every object available in the JVM heap space and removes unwanted ones.
|
||||
Garbage collector works in two simple steps known as Mark and Sweep:
|
||||
|
||||
Mark – it is where the garbage collector identifies which piece of memory is in use and which are not
|
||||
|
||||
|
||||
Sweep – it removes objects identified during the “mark” phase.
|
||||
|
||||
**8) Native Method interface**
|
||||
|
||||
The Native Method Interface is a programming framework. It allows Java code, which is running in a JVM to call by libraries and native applications.
|
||||
|
||||
**9) Native Method Libraries**
|
||||
|
||||
Native Libraries is a collection of the Native Libraries (C, C++), which are needed by the Execution Engine.
|
||||
|
||||
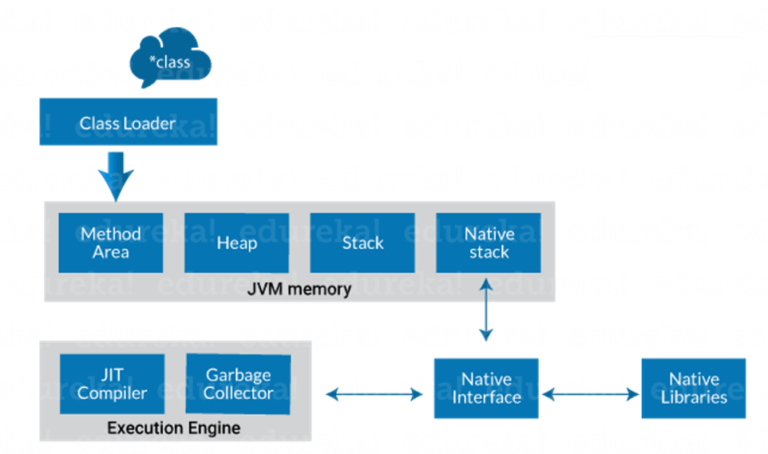
|
||||
|
||||
----
|
||||
|
||||
|
||||
|
||||
@@ -0,0 +1,263 @@
|
||||

|
||||
------
|
||||
# Understanding Static and Final Keyword in Java
|
||||
|
||||
## Static Keyword
|
||||
Java uses static keyword at 4 different places. Lets learn about each of them.
|
||||
- Static Instance Variables
|
||||
- Static Methods
|
||||
- Static Block
|
||||
- Static Classes.
|
||||
|
||||
**Static Members and Methods**
|
||||
There will be times when you will want to define a class member that will be used independently of any object of that class. Normally, a class member must be accessed only in conjunction with an object of its class. However, it is possible to create a member that can be used by itself, without reference to a specific instance.
|
||||
|
||||
To create such a member, precede its declaration with the keyword static. When a member is declared `static`, it can be accessed before any objects of its class are created, and without reference to any object. You can declare both methods and variables to be static.
|
||||
|
||||
The most common example of a static member is main( ). main( ) is declared as static because it must be called before any objects exist.
|
||||
|
||||
Instance variables declared as static are, essentially, global variables. When objects of its class are declared, no copy of a static variable is made. Instead, all instances of the class share the same static variable.
|
||||
|
||||
**Math.java**
|
||||
```java
|
||||
public class Math {
|
||||
static String author = "Prateek";
|
||||
|
||||
static int area(int l,int b){
|
||||
return l*b;
|
||||
}
|
||||
}
|
||||
```
|
||||
In the above example the static keywod has been used to create a static data member and a static method. We don't need create a Math Class objects to acess the methods and data members, instead we can directly refer `Math.author` and `Math.area(v1,v2)` from main.
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
//static block will execute when the class is loaded
|
||||
|
||||
System.out.println("Area of Rectangle " + Math.area(10,20));
|
||||
System.out.println(Math.author);
|
||||
}
|
||||
```
|
||||
|
||||
**Restrictions on Static Methods**:
|
||||
|
||||
• They can only directly call other static methods of their class.
|
||||
|
||||
• They can only directly access static variables of their class.
|
||||
|
||||
• They cannot refer to `this` or `super` in any way. (Super keyword is used in inheritance)
|
||||
|
||||
|
||||
**Static Block**
|
||||
If you need to do computation in order to initialize your static variables, you can declare a static block that gets executed exactly once, when the class is first loaded.
|
||||
As soon as the class is loaded, all of the static statements are run.
|
||||
|
||||
```java
|
||||
public class StaticDemoExample {
|
||||
static int a = 3;
|
||||
static int b;
|
||||
|
||||
static{
|
||||
System.out.println("Inside Static Block");
|
||||
b = a*4;
|
||||
printData();
|
||||
}
|
||||
|
||||
static void printData(){
|
||||
System.out.println(a);
|
||||
System.out.println(b);
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
//static block will execute when the class is loaded
|
||||
// it is used to init static variables
|
||||
}
|
||||
}
|
||||
```
|
||||
In the above code, static block will automatically as you launch the program, the class is loaded and static block is executed. Despite the main being empty, the code will output the following as static block is still executed.
|
||||
|
||||
*Code Output*
|
||||
```
|
||||
Inside Static Block
|
||||
3
|
||||
12
|
||||
```
|
||||
|
||||
## Nested Classes and 'Static' Modifier
|
||||
It is possible to define a class within another class; such classes are known as nested classes. There are two types of nested classes: static and non-static. Lets learn about them.
|
||||
|
||||
**Static Nested Class (Static Inner Class)**:
|
||||
- A static nested class is a nested class that is declared as static.
|
||||
- It does not have access to the instance-specific members of the outer class.Because it is static, it must access the non-static members of its enclosing class through an object.
|
||||
- You can create an instance of a static nested class without creating an instance of the outer class.
|
||||
- Static nested classes are often used for grouping related utility methods or encapsulating code within a class.
|
||||
- Note: In Java, only nested classes are allowed to be static.
|
||||
|
||||
|
||||
```java
|
||||
public class OuterClass {
|
||||
// Outer class members
|
||||
|
||||
static class StaticNestedClass {
|
||||
// Static nested class members
|
||||
}
|
||||
}
|
||||
```
|
||||
**Inner Class (Non-static Nested Class)**
|
||||
|
||||
- An inner class is a nested class that is not declared as static.
|
||||
- It can access both static and instance-specific members of the outer class.
|
||||
- An instance of an inner class can only be created within an instance of the outer class.
|
||||
- Inner classes are often used for implementing complex data structures or for achieving better encapsulation.
|
||||
|
||||
```java
|
||||
public class OuterClass {
|
||||
// Outer class members
|
||||
|
||||
class InnerClass {
|
||||
// Inner class members
|
||||
}
|
||||
}
|
||||
```
|
||||
**Nested Static Classes in Builder Design Pattern**
|
||||
This kind of class design is particularly useful in Builder Design Pattern which you will study later as a part of Low Level Design Course. In short, The Builder Design Pattern is a creational design pattern that allows you to create complex objects step by step. It's especially useful when you have an object with many optional parameters or configurations. Here's an example of how you can implement the Builder pattern in Java:
|
||||
|
||||
Suppose you want to create a Person class with optional attributes like name, age, address, and phone number using the Builder pattern:
|
||||
|
||||
```java
|
||||
public class Person {
|
||||
private String name;
|
||||
private int age;
|
||||
private String address;
|
||||
private String phoneNumber;
|
||||
|
||||
// Private constructor to prevent direct instantiation
|
||||
private Person() {
|
||||
}
|
||||
|
||||
// Nested Builder class
|
||||
public static class Builder {
|
||||
private String name;
|
||||
private int age;
|
||||
private String address;
|
||||
private String phoneNumber;
|
||||
|
||||
public Builder(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
|
||||
public Builder age(int age) {
|
||||
this.age = age;
|
||||
return this;
|
||||
}
|
||||
|
||||
public Builder address(String address) {
|
||||
this.address = address;
|
||||
return this;
|
||||
}
|
||||
|
||||
public Builder phoneNumber(String phoneNumber) {
|
||||
this.phoneNumber = phoneNumber;
|
||||
return this;
|
||||
}
|
||||
|
||||
public Person build() {
|
||||
Person person = new Person();
|
||||
person.name = this.name;
|
||||
person.age = this.age;
|
||||
person.address = this.address;
|
||||
person.phoneNumber = this.phoneNumber;
|
||||
return person;
|
||||
}
|
||||
}
|
||||
|
||||
// Getter methods for Person class
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
|
||||
public int getAge() {
|
||||
return age;
|
||||
}
|
||||
|
||||
public String getAddress() {
|
||||
return address;
|
||||
}
|
||||
|
||||
public String getPhoneNumber() {
|
||||
return phoneNumber;
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString() {
|
||||
return "Name: " + name + ", Age: " + age + ", Address: " + address + ", Phone: " + phoneNumber;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
__PersonDemo.java__
|
||||
```java
|
||||
public class PersonDemo {
|
||||
public static void main(String[] args) {
|
||||
Person person1 = new Person.Builder("John")
|
||||
.age(30)
|
||||
.address("123 Main St")
|
||||
.phoneNumber("555-1234")
|
||||
.build();
|
||||
|
||||
Person person2 = new Person.Builder("Alice")
|
||||
.age(25)
|
||||
.phoneNumber("555-5678")
|
||||
.build();
|
||||
|
||||
System.out.println(person1);
|
||||
System.out.println(person2);
|
||||
}
|
||||
}
|
||||
```
|
||||
This allows you to create Person objects with various combinations of attributes while keeping the code clean and readable.
|
||||
|
||||
|
||||
|
||||
------------------
|
||||
### Final Keyword
|
||||
The keyword final has three uses. First, it can be used to create the equivalent of a named constant. The other two uses of final apply to inheritance as discussed below.
|
||||
|
||||
**1. Final in Variables**
|
||||
A field can be declared as final. Doing so prevents its contents from being modified, making it, essentially, a constant. This means that you must initialize a final field when it is declared. You can do this in one of two ways: First, you can give it a value when it is declared. Second, you can assign it a value within a constructor. The first approach is probably the most common. Here is an example:
|
||||
```
|
||||
final int FILE_NEW = 1;
|
||||
final int FILE_OPEN = 2;
|
||||
final int FILE_SAVE = 3;
|
||||
final int FILE_SAVEAS = 4;
|
||||
final int FILE_QUIT = 5;
|
||||
```
|
||||
|
||||
Subsequent parts of your program can now use FILE_OPEN, etc., as if they were constants, without fear that a value has been changed. It is a common coding convention to choose all **uppercase identifiers** for final fields, as this example shows.
|
||||
|
||||
In addition to fields, both method parameters and local variables can be declared final. Declaring a parameter final prevents it from being changed within the method. Declaring a local variable final prevents it from being assigned a value more than once.
|
||||
|
||||
The keyword final can also be applied to methods, but its meaning is substantially different than when it is applied to variables.
|
||||
|
||||
|
||||
**2. Using final to Prevent Method Overriding**
|
||||
While method overriding is one of Java’s most powerful features, there will be times when you will want to prevent it from occurring. To disallow a method from being overridden, specify final as a modifier at the start of its declaration. Methods declared as final cannot be overridden. The following fragment illustrates final.
|
||||
|
||||

|
||||
Because meth( ) is declared as final, it cannot be overridden in B. If you attempt to do so, a compile-time error will result.
|
||||
|
||||
Methods declared as final can sometimes provide a performance enhancement: The compiler is free to inline calls to them because it “knows” they will not be overridden by a subclass. When a small final method is called, often the Java compiler can copy the bytecode for the subroutine directly inline with the compiled code of the calling method, thus eliminating the costly overhead associated with a method call. Inlining is an option only with final methods. Normally, Java resolves calls to methods dynamically, at run time. This is called late binding. However, since final methods cannot be overridden, a call to one can be resolved at compile time. This is called early binding.
|
||||
|
||||
**3. Using final to Prevent Inheritance**
|
||||
Sometimes you will want to prevent a class from being inherited. To do this, precede the class declaration with final. Declaring a class as final implicitly declares all of its methods as final, too. As you might expect, it is illegal to declare a class as both abstract and final since an abstract class is incomplete by itself and relies upon its subclasses to provide complete implementations.
|
||||
|
||||
Here is an example of a final class:
|
||||

|
||||
As the comments imply, it is illegal for B to inherit A since A is declared as final.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -0,0 +1,226 @@
|
||||
### Java Streams
|
||||
A stream in Java is simply a wrapper around a data source, allowing us to perform bulk operations on the data in a convenient way.
|
||||
|
||||
It doesn’t store data or make any changes to the underlying data source. Rather, it adds support for functional-style operations on data pipelines.
|
||||
|
||||
In this tutorial we will learn about Sequential Streams, Parallel Streams and Collect() Method of stream.
|
||||
|
||||
### Sequential Streams
|
||||
By default, any stream operation in Java is processed sequentially, unless explicitly specified as parallel.
|
||||
|
||||
Sequential streams use a single thread to process the pipeline:
|
||||
```java
|
||||
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
|
||||
listOfNumbers.stream().forEach(number ->
|
||||
System.out.println(number + " " + Thread.currentThread().getName())
|
||||
);
|
||||
```
|
||||
The output of this sequential stream is predictable. The list elements will always be printed in an ordered sequence:
|
||||
|
||||
```
|
||||
1 main
|
||||
2 main
|
||||
3 main
|
||||
4 main
|
||||
```
|
||||
|
||||
### Multithreading using Parallel Streams
|
||||
Stream API also simplifies multithreading by providing the `parallelStream()` method that runs operations over stream’s elements in parallel mode. Any stream in Java can easily be transformed from sequential to parallel.
|
||||
|
||||
We can achieve this by adding the parallel method to a sequential stream or by creating a stream using the parallelStream method of a collection:
|
||||
|
||||
The code below allows to run method doWork() in parallel for every element of the stream:
|
||||
```java
|
||||
list.parallelStream().forEach(element -> doWork(element));
|
||||
```
|
||||
For the above sequential example, the code will looks like this -
|
||||
|
||||
```java
|
||||
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
|
||||
listOfNumbers.parallelStream().forEach(number ->
|
||||
System.out.println(number + " " + Thread.currentThread().getName())
|
||||
);
|
||||
```
|
||||
Parallel streams enable us to execute code in parallel on separate cores. The final result is the combination of each individual outcome.
|
||||
|
||||
However, the order of execution is out of our control. It may change every time we run the program:
|
||||
```
|
||||
4 ForkJoinPool.commonPool-worker-3
|
||||
2 ForkJoinPool.commonPool-worker-5
|
||||
1 ForkJoinPool.commonPool-worker-7
|
||||
3 main
|
||||
```
|
||||
Parallel streams make use of the fork-join framework and its common pool of worker threads. Parallel processing may be beneficial to fully utilize multiple cores. But we also need to consider the overhead of managing multiple threads, memory locality, splitting the source and merging the results.
|
||||
Refer this [Article](https://www.baeldung.com/java-when-to-use-parallel-stream) to learn more about when to use parallel streams.
|
||||
|
||||
`
|
||||
|
||||
### Collect() Method
|
||||
|
||||
A stream represents a sequence of elements and supports different kinds of operations that lead to the desired result. The source of a stream is usually a Collection or an Array, from which data is streamed from.
|
||||
|
||||
Streams differ from collections in several ways; most notably in that the streams are not a data structure that stores elements. They're functional in nature, and it's worth noting that operations on a stream produce a result and typically return another stream, but do not modify its source.
|
||||
|
||||
To "solidify" the changes, you **collect** the elements of a stream back into a Collection.
|
||||
|
||||
The `stream.collect()` method is used to perform a mutable reduction operation on the elements of a stream. It returns a new mutable object containing the results of the reduction operation.
|
||||
|
||||
This method can be used to perform several different types of reduction operations, such as:
|
||||
|
||||
- Computing the sum of numeric values in a stream.
|
||||
- Finding the minimum or maximum value in a stream.
|
||||
- Constructing a new String by concatenating the contents of a stream.
|
||||
- Collecting elements into a new List or Set.
|
||||
|
||||
```java
|
||||
public class CollectExample {
|
||||
public static void main(String[] args) {
|
||||
Integer[] intArray = {1, 2, 3, 4, 5};
|
||||
|
||||
// Creating a List from an array of elements
|
||||
// using Arrays.asList() method
|
||||
List<Integer> list = Arrays.asList(intArray);
|
||||
|
||||
// Demo1: Collecting all elements of the list into a new
|
||||
// list using collect() method
|
||||
List<Integer> evenNumbersList = list.stream()
|
||||
.filter(i -> i%2 == 0)
|
||||
.collect(toList());
|
||||
System.out.println(evenNumbersList);
|
||||
|
||||
// Demo2: finding the sum of all the values
|
||||
// in the stream
|
||||
Integer sum = list.stream()
|
||||
.collect(summingInt(i -> i));
|
||||
System.out.println(sum);
|
||||
|
||||
// Demo3: finding the maximum of all the values
|
||||
// in the stream
|
||||
Integer max = list.stream()
|
||||
.collect(maxBy(Integer::compare)).get();
|
||||
System.out.println(max);
|
||||
|
||||
// Demo4: finding the minimum of all the values
|
||||
// in the stream
|
||||
Integer min = list.stream()
|
||||
.collect(minBy(Integer::compare)).get();
|
||||
System.out.println(min);
|
||||
|
||||
// Demo5: counting the values in the stream
|
||||
Long count = list.stream()
|
||||
.collect(counting());
|
||||
System.out.println(count);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
In Demo1: We use the stream() method to get a stream from the list. We filter the even elements and collect them into a new list using the collect() method.
|
||||
|
||||
In Demo2: We use the collect() method summingInt(ToIntFunction) as an argument. The summingInt() method returns a collector that sums the integer values extracted from the stream elements by applying an int producing mapping function to each element.
|
||||
|
||||
In Demo 3: We use the collect() method with maxBy(Comparator) as an argument. The maxBy() accepts a Comparator and returns a collector that extracts the maximum element from the stream according to the given Comparator.
|
||||
|
||||
Lets learn more about Collectors.
|
||||
|
||||
|
||||
### Collectors and Stream.Collect()
|
||||
|
||||
Collectors represent implementations of the Collector interface, which implements various useful reduction operations, such as accumulating elements into collections, summarizing elements based on a specific parameter, etc.
|
||||
|
||||
All predefined implementations can be found within the [Collectors](https://docs.oracle.com/javase/8/docs/api/java/util/stream/Collectors.html) class.
|
||||
|
||||
|
||||
Within the Collectors class itself, we find an abundance of unique methods that deliver on the different needs of a user. One such group is made of summing methods - `summingInt()`, `summingDouble()` and `summingLong()`.
|
||||
|
||||
|
||||
|
||||
Let's start off with a basic example with a List of Integers:
|
||||
|
||||
```java
|
||||
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
|
||||
Integer sum = numbers.stream().collect(Collectors.summingInt(Integer::intValue));
|
||||
System.out.println("Sum: " + sum);
|
||||
```
|
||||
We apply the .stream() method to create a stream of Integer instances, after which we use the previously discussed `.collect()` method to collect the elements using `summingInt()`. The method itself, again, accepts the `ToIntFunction`, which can be used to reduce instances to an integer that can be summed.
|
||||
|
||||
Since we're using Integers already, we can simply pass in a method reference denoting their `intValue`, as no further reduction is needed.
|
||||
|
||||
More often than not - you'll be working with lists of custom objects and would like to sum some of their fields. For instance, we can sum the quantities of each product in the productList, denoting the total inventory we have.
|
||||
|
||||
Let us try to understand one of these methods using a custom class example.
|
||||
``` java
|
||||
public class Product {
|
||||
private String name;
|
||||
private Integer quantity;
|
||||
private Double price;
|
||||
private Long productNumber;
|
||||
|
||||
// Constructor, getters and setters
|
||||
...
|
||||
}
|
||||
...
|
||||
List<Product> products = Arrays.asList(
|
||||
new Product("Milk", 37, 3.60, 12345600L),
|
||||
new Product("Carton of Eggs", 50, 1.20, 12378300L),
|
||||
new Product("Olive oil", 28, 37.0, 13412300L),
|
||||
new Product("Peanut butter", 33, 4.19, 15121200L),
|
||||
new Product("Bag of rice", 26, 1.70, 21401265L)
|
||||
);
|
||||
|
||||
```
|
||||
|
||||
In such a case, the we can use a method reference, such as `Product::getQuantity` as our `ToIntFunction`, to reduce the objects into a single integer each, and then sum these integers:
|
||||
|
||||
```java
|
||||
Integer sumOfQuantities = products.stream().collect(Collectors.summingInt(Product::getQuantity));
|
||||
System.out.println("Total number of products: " + sumOfQuantities);
|
||||
```
|
||||
This results in:
|
||||
|
||||
```
|
||||
Total number of products: 174
|
||||
```
|
||||
|
||||
You can also very easily implement your own collector and use it instead of the predefined ones, though - you can get pretty far with the built-in collectors, as they cover the vast majority of cases in which you might want to use them.
|
||||
|
||||
The following are examples of using the predefined collectors to perform common mutable reduction tasks:
|
||||
```java
|
||||
|
||||
// Accumulate names into a List
|
||||
List<String> list = people.stream().map(Person::getName).collect(Collectors.toList());
|
||||
|
||||
// Accumulate names into a TreeSet
|
||||
Set<String> set = people.stream().map(Person::getName).collect(Collectors.toCollection(TreeSet::new));
|
||||
|
||||
// Convert elements to strings and concatenate them, separated by commas
|
||||
String joined = things.stream()
|
||||
.map(Object::toString)
|
||||
.collect(Collectors.joining(", "));
|
||||
|
||||
// Compute sum of salaries of employee
|
||||
int total = employees.stream()
|
||||
.collect(Collectors.summingInt(Employee::getSalary)));
|
||||
|
||||
// Group employees by department
|
||||
Map<Department, List<Employee>> byDept
|
||||
= employees.stream()
|
||||
.collect(Collectors.groupingBy(Employee::getDepartment));
|
||||
|
||||
// Compute sum of salaries by department
|
||||
Map<Department, Integer> totalByDept
|
||||
= employees.stream()
|
||||
.collect(Collectors.groupingBy(Employee::getDepartment,
|
||||
Collectors.summingInt(Employee::getSalary)));
|
||||
|
||||
// Partition students into passing and failing
|
||||
Map<Boolean, List<Student>> passingFailing =
|
||||
students.stream()
|
||||
.collect(Collectors.partitioningBy(s -> s.getGrade() >= PASS_THRESHOLD));
|
||||
|
||||
```
|
||||
You can look at the offical documentation for more details on these methods.
|
||||
https://docs.oracle.com/javase/8/docs/api/java/util/stream/Collectors.html
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -0,0 +1,173 @@
|
||||
# Java Strings - Advanced Concepts
|
||||
In this tutorial we discuss 3 important concepts related to Strings.
|
||||
- String Pool
|
||||
- String Immutability
|
||||
- String Builder
|
||||
|
||||
|
||||
String are handled differently in Java. There are two ways to store strings - one as string literals stored in String Pool and as string objects stored in regular heap space. Lets discuss about them.
|
||||
|
||||
### 1. Strings in String Pool
|
||||
Each time you create a string literal, the JVM checks the "string constant pool" first. If the string already exists in the pool, a reference to the pooled instance is returned. If the string doesn't exist in the pool, a new string instance is created and placed in the pool. For example:
|
||||
|
||||
**String Literal Syntax**
|
||||
```java
|
||||
String s1 = "Hello World";
|
||||
String s2 = "Hello World";//It doesn't create a new instance
|
||||
```
|
||||
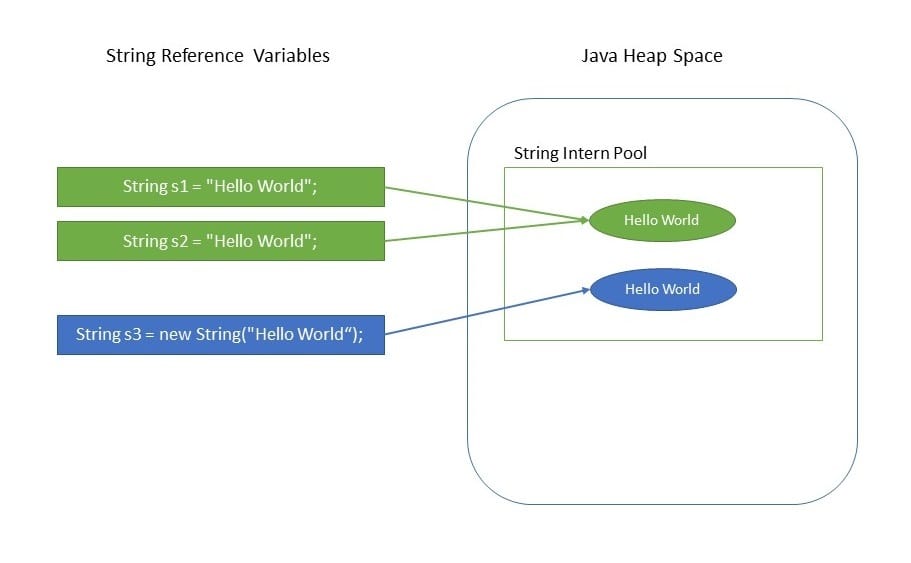
|
||||
|
||||
In the above example, only one object will be created. Firstly, JVM will not find any string object with the value "Hello World" in string constant pool that is why it will create a new object. After that it will find the string with the value "Hello World" in the pool, it will not create a new object but will return the reference to the same instance.
|
||||
|
||||
**Java String Pool** is the special memory region where Strings are stored by the JVM. Since Strings are immutable in Java, the JVM optimizes the amount of memory allocated for them by storing only one copy of each literal String in the pool. This process is called interning
|
||||
|
||||
### 2. String Allocated Using the Constructor
|
||||
When we create a String via the new operator, the Java compiler will create a new object and store it in the heap space reserved for the JVM.
|
||||
|
||||
Every String created like this will point to a different memory region with its own address.
|
||||
|
||||
Let’s see how this is different from the previous case:
|
||||
|
||||
```java
|
||||
String s1 = new String("Welcome");
|
||||
String s2 = new String("Welcome");
|
||||
//creates two objects and two reference variables point to different addresses
|
||||
```
|
||||
---
|
||||
### Big Question - String Literal vs String Object?
|
||||
We have just seen that when we create a String object using the `new()` operator, it always creates a new object in heap memory. On the other hand, if we create an object using String literal syntax e.g. “Hello World”, it may return an existing object from the String pool, if it already exists. Otherwise, it will create a new String object and put in the string pool for future re-use.
|
||||
|
||||
At a high level, both are the String objects, but the main difference comes from the point that new() operator always creates a new String object. Also, when we create a String using literal – it is interned.
|
||||
|
||||
In general, we should use the String literal notation when possible. It is easier to read and it gives the compiler a chance to optimize our code.
|
||||
|
||||
----
|
||||
|
||||
## Immutablibity of Java Strings
|
||||
|
||||
*Immutable* simply means unmodifiable or unchangeable. This means that once the object has been assigned to a variable, we can neither update the reference nor change the internal state by any means.
|
||||
|
||||
In Java, Strings are immutable. An obvious question that is quite prevalent in interviews is “Why Strings are designed as immutable in Java?” The key benefits of keeping this class as immutable are caching, security, synchronization, and performance.
|
||||
|
||||
Let’s discuss how these things work.
|
||||
|
||||
#### Why String objects are immutable in Java?
|
||||
As Java uses the concept of String literal. Suppose there are 5 reference variables, all refer to one object "Sachin". If one reference variable changes the value of the object, it will be affected by all the reference variables. That is why String objects are immutable in Java.
|
||||
|
||||
Following are some more features of String which makes String objects immutable.
|
||||
|
||||
**1. Heap Space**
|
||||
The immutability of String helps to minimize the usage in the heap memory. When we try to declare a new String object, the JVM checks whether the value already exists in the String pool or not. If it exists, the same value is assigned to the new object. This feature allows Java to use the heap space efficiently.
|
||||
|
||||
Java String Pool is the special memory region where Strings are stored by the JVM. Since Strings are immutable in Java, the JVM optimizes the amount of memory allocated for them by storing only one copy of each literal String in the pool. This process is called **interning**
|
||||
|
||||
**2. Security**
|
||||
The String is widely used in Java applications to store sensitive pieces of information like usernames, passwords, connection URLs, network connections, etc. It’s also used extensively by JVM class loaders while loading classes.
|
||||
|
||||
Hence securing String class is crucial regarding the security of the whole application in general. For example, consider this simple code snippet:
|
||||
|
||||
```java
|
||||
void criticalMethod(String userName) {
|
||||
// perform security checks
|
||||
if (!isAlphaNumeric(userName)) {
|
||||
throw new SecurityException();
|
||||
}
|
||||
|
||||
// do some secondary tasks
|
||||
initializeDatabase();
|
||||
|
||||
// critical task
|
||||
connection.executeUpdate("UPDATE Customers SET Status = 'Active' " +
|
||||
" WHERE UserName = '" + userName + "'");
|
||||
}
|
||||
```
|
||||
|
||||
In the above code snippet, let’s say that we received a String object from an untrustworthy source. We’re doing all necessary security checks initially to check if the String is only alphanumeric, followed by some more operations.
|
||||
|
||||
Remember that our unreliable source caller method still has reference to this userName object.
|
||||
|
||||
If Strings were mutable, then by the time we execute the update, we can’t be sure that the String we received, even after performing security checks, would be safe. The untrustworthy caller method still has the reference and can change the String between integrity checks. Thus making our query prone to SQL injections in this case. So mutable Strings could lead to degradation of security over time.
|
||||
|
||||
It could also happen that the String userName is visible to another thread, which could then change its value after the integrity check.
|
||||
|
||||
**3. Synchronization**
|
||||
Being immutable automatically makes the String thread safe since they won’t be changed when accessed from multiple threads.
|
||||
|
||||
Hence immutable objects, in general, can be shared across multiple threads running simultaneously. They’re also thread-safe because if a thread changes the value, then instead of modifying the same, a new String would be created in the String pool. Hence, Strings are safe for multi-threading.
|
||||
|
||||
**4. Hashcode Caching**
|
||||
Since String objects are abundantly used as a data structure, they are also widely used in hash implementations like HashMap, HashTable, HashSet, etc. When operating upon these hash implementations, hashCode() method is called quite frequently for bucketing.
|
||||
|
||||
The immutability guarantees Strings that their value won’t change. So the hashCode() method is overridden in String class to facilitate caching, such that the hash is calculated and cached during the first hashCode() call and the same value is returned ever since.
|
||||
|
||||
This, in turn, improves the performance of collections that uses hash implementations when operated with String objects.
|
||||
|
||||
On the other hand, mutable Strings would produce two different hashcodes at the time of insertion and retrieval if contents of String was modified after the operation, potentially losing the value object in the Map.
|
||||
|
||||
-----
|
||||
|
||||
# String Builder Class
|
||||
|
||||
String builder is a class that represents a *mutable sequence* of characters.
|
||||
Both StringBuilder and StringBuffer create objects that hold a mutable sequence of characters. Let’s see how this works, and how it compares to an immutable String class:
|
||||
|
||||
```java
|
||||
String immutable = "abc";
|
||||
immutable = immutable + "def";
|
||||
```
|
||||
Even though it may look like that we’re modifying the same object by appending “def”, we are creating a new one because String instances can’t be modified.
|
||||
|
||||
When using either StringBuffer or StringBuilder, we can use the append() method:
|
||||
```java
|
||||
StringBuffer sb = new StringBuffer("abc");
|
||||
sb.append("def");
|
||||
```
|
||||
In this case, there was no new object created. We have called the append() method on sb instance and modified its content. StringBuffer and StringBuilder are mutable objects.
|
||||
|
||||
You can look at more methods available in string buffer at [official documentation](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/lang/StringBuilder.html).
|
||||
|
||||
Some of the commonly used methods are `toString()`, `insert()`, 'delete()',`append()`, `getChars()` etc.
|
||||
|
||||
|
||||
**String Builder Demo**
|
||||
```java
|
||||
public class StringBuilderExample {
|
||||
|
||||
static void generateString(){
|
||||
String s = "";
|
||||
//Adding to String Object
|
||||
// Inffecient Runs in O(n*n)
|
||||
for(int i=0; i<100000;i++){
|
||||
s = s + (char)('A' + i); //inefficient
|
||||
}
|
||||
return s;
|
||||
}
|
||||
|
||||
static void generateStringUsingSB(){
|
||||
StringBuilder sb = new StringBuilder();
|
||||
//Efficient
|
||||
//Runs in O(N)
|
||||
for(int i=0; i<100000;i++){
|
||||
sb.append((char)('A' + i)); //efficient
|
||||
}
|
||||
return sb.toString();
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
//you can do a time comparison for both
|
||||
long start = System.currentTimeMillis();
|
||||
generateStringUsingSB();
|
||||
long end = System.currentTimeMillis();
|
||||
System.out.println(end-start);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
**String Buffer vs String Builder**
|
||||
StringBuffer is synchronized and therefore thread-safe. StringBuilder is compatible with StringBuffer API but with no guarantee of synchronization.Because it’s not a thread-safe implementation, it is faster and it is recommended to use it in places where there’s no need for thread safety
|
||||
|
||||
|
||||
Simply put, the StringBuffer is a thread-safe implementation and therefore slower than the StringBuilder. In single-threaded programs, we can take of the StringBuilder. Yet, the performance gain of StringBuilder over StringBuffer may be too small to justify replacing it everywhere.
|
||||
|
||||
|
||||
@@ -0,0 +1,283 @@
|
||||
### Threads in Java Recap
|
||||
In the Java, multithreading is driven by the core concept of a Thread. Lets recap some logic that runs in a parallel thread by using the Thread framework. In the below code example we are creating two threads and running them in parallel.
|
||||
|
||||
**Using Thread Class**
|
||||
```java
|
||||
public class NewThread extends Thread {
|
||||
public void run() {
|
||||
// business logic
|
||||
...
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
Class to initialize and start our thread.
|
||||
|
||||
```java
|
||||
public class MultipleThreadsExample {
|
||||
public static void main(String[] args) {
|
||||
NewThread t1 = new NewThread();
|
||||
t1.setName("MyThread-1");
|
||||
NewThread t2 = new NewThread();
|
||||
t2.setName("MyThread-2");
|
||||
t1.start();
|
||||
t2.start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Using Runnable**
|
||||
```java
|
||||
class SimpleRunnable implements Runnable {
|
||||
public void run() {
|
||||
// business logic
|
||||
}
|
||||
}
|
||||
```
|
||||
The above SimpleRunnable is just a task which we want to run in a separate thread.
|
||||
There’re various approaches we can use for running it; one of them is to use the Thread class:
|
||||
|
||||
```java
|
||||
public void test(){
|
||||
Thread thread = new Thread(new SimpleRunnable());
|
||||
thread.start();
|
||||
thread.join();
|
||||
}
|
||||
```
|
||||
|
||||
Simply put, we generally encourage the use of Runnable over Thread:
|
||||
|
||||
When extending the Thread class, we’re not overriding any of its methods. Instead, we override the method of Runnable (which Thread happens to implement).
|
||||
- This is a clear violation of IS-A Thread principle
|
||||
- Creating an implementation of Runnable and passing it to the Thread class utilizes composition and not inheritance – which is more flexible
|
||||
- After extending the Thread class, we can’t extend any other class
|
||||
- From Java 8 onwards, Runnables can be represented as lambda expressions
|
||||
|
||||
### Thread Life Cycle
|
||||
During thread lifecycle, threads go through various states. The `java.lang.Thread` class contains a static State enum – which defines its potential states. During any given point of time, the thread can only be in one of these states:
|
||||
|
||||
- **NEW** – a newly created thread that has not yet started the execution
|
||||
- **RUNNABLE** – either running or ready for execution but it’s waiting for resource allocation
|
||||
- **BLOCKED** – waiting to acquire a monitor lock to enter or re-enter a synchronized block/method
|
||||
- **WAITING** – waiting for some other thread to perform a particular action without any time limit
|
||||
- **TIMED_WAITING** – waiting for some other thread to perform a specific action for a specified period
|
||||
- **TERMINATED** – has completed its execution
|
||||
|
||||
#### 1.NEW
|
||||
A NEW Thread (or a Born Thread) is a thread that’s been created but not yet started. It remains in this state until we start it using the start() method.
|
||||
|
||||
The following code snippet shows a newly created thread that’s in the NEW state:
|
||||
|
||||
```java
|
||||
Runnable runnable = new NewState();
|
||||
Thread t = new Thread(runnable);
|
||||
System.out.println(t.getState());
|
||||
```
|
||||
|
||||
Since we’ve not started the mentioned thread, the method `t.getState()` prints:
|
||||
```
|
||||
NEW
|
||||
```
|
||||
|
||||
### 2. Runnable
|
||||
When we’ve created a new thread and called the start() method on that, it’s moved from NEW to RUNNABLE state. Threads in this state are either running or ready to run, but they’re waiting for resource allocation from the system.
|
||||
|
||||
In a multi-threaded environment, the Thread-Scheduler (which is part of JVM) allocates a fixed amount of time to each thread. So it runs for a particular amount of time, then leaves the control to other RUNNABLE threads.
|
||||
|
||||
For example, let’s add `t.start()` method to our previous code and try to access its current state:
|
||||
|
||||
```java
|
||||
Runnable runnable = new NewState();
|
||||
Thread t = new Thread(runnable);
|
||||
t.start();
|
||||
System.out.println(t.getState());
|
||||
```
|
||||
|
||||
This code is most likely to return the output as:
|
||||
```
|
||||
RUNNABLE
|
||||
```
|
||||
Note that in this example, it’s not always guaranteed that by the time our control reaches `t.getState()`, it will be still in the RUNNABLE state.
|
||||
|
||||
It may happen that it was immediately scheduled by the Thread-Scheduler and may finish execution. In such cases, we may get a different output.
|
||||
|
||||
### 3. BLOCKED
|
||||
A thread is in the BLOCKED state when it’s currently not eligible to run. It enters this state when it is waiting for a monitor lock and is trying to access a section of code that is locked by some other thread.
|
||||
|
||||
Let’s try to reproduce this state:
|
||||
```java
|
||||
public class BlockedState {
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
Thread t1 = new Thread(new DemoBlockedRunnable());
|
||||
Thread t2 = new Thread(new DemoBlockedRunnable());
|
||||
|
||||
t1.start();
|
||||
t2.start();
|
||||
|
||||
Thread.sleep(1000); //pause so that t2 states changes during this time
|
||||
System.out.println(t2.getState());
|
||||
System.exit(0);
|
||||
}
|
||||
}
|
||||
|
||||
class DemoBlockedRunnable implements Runnable {
|
||||
@Override
|
||||
public void run() {
|
||||
commonResource();
|
||||
}
|
||||
|
||||
public static synchronized void commonResource() {
|
||||
while(true) {
|
||||
// Infinite loop to mimic heavy processing
|
||||
// 't1' won't leave this method
|
||||
// when 't2' try to enter this
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
In this code:
|
||||
|
||||
We’ve created two different threads – t1 and t2, t1 starts and enters the synchronized commonResource() method; this means that only one thread can access it; all other subsequent threads that try to access this method will be blocked from the further execution until the current one will finish the processing.
|
||||
|
||||
When t1 enters this method, it is kept in an infinite while loop; this is just to imitate heavy processing so that all other threads cannot enter this method
|
||||
|
||||
Now when we start t2, it tries to enter the commonResource() method, which is already being accessed by t1, thus, t2 will be kept in the BLOCKED state.
|
||||
Being in this state, we call `t2.getState()` and get the output as:
|
||||
```
|
||||
BLOCKED
|
||||
```
|
||||
|
||||
### 4. WAITING
|
||||
A thread is in WAITING state when it’s waiting for some other thread to perform a particular action. According to JavaDocs, any thread can enter this state by calling any one of the following three methods:
|
||||
|
||||
- object.wait()
|
||||
- thread.join() or
|
||||
- LockSupport.park()
|
||||
|
||||
Note that in wait() and join() – we do not define any timeout period as that scenario is covered in the next section.
|
||||
|
||||
|
||||
In this example, thread-1 starts thread 2 and waits for thread-2 to finish using `thread.join()` method. During this time t1 is in `WAITING` state.
|
||||
|
||||
**Simple Runnable.java - Thread 1**
|
||||
```java
|
||||
public class SimpleRunnable implements Runnable{
|
||||
|
||||
@Override
|
||||
public void run(){
|
||||
Thread t2 = new Thread(new SimpleRunnableTwo());
|
||||
t2.start();
|
||||
try {
|
||||
t2.join();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
**Simple Runnable 2 - Thread 2**
|
||||
```java
|
||||
public class SimpleRunnableTwo implements Runnable {
|
||||
@Override
|
||||
public void run() {
|
||||
try{
|
||||
Thread.sleep(5000);
|
||||
}
|
||||
catch(InterruptedException e){
|
||||
Thread.currentThread().interrupt();
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
**Main**
|
||||
```java
|
||||
public class Main {
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
Thread t1 = new Thread(new SimpleRunnable());
|
||||
t1.start();
|
||||
|
||||
Thread.sleep(1000); //1ms pause
|
||||
System.out.println("T1 :"+ t1.getState()); //T1 is waiting state
|
||||
System.out.println("Main :" + Thread.currentThread().getState());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 5. TIMED WAITING
|
||||
A thread is in `TIMED_WAITING` state when it’s waiting for another thread to perform a particular action within a stipulated amount of time.
|
||||
|
||||
According to JavaDocs, there are five ways to put a thread on TIMED_WAITING state:
|
||||
|
||||
- thread.sleep(long millis)
|
||||
- wait(int timeout) or wait(int timeout, int nanos)
|
||||
- thread.join(long millis)
|
||||
- LockSupport.parkNanos
|
||||
- LockSupport.parkUntil
|
||||
|
||||
Here, we’ve created and started a thread t1 which is entered into the sleep state with a timeout period of 5 seconds; the output will be `TIMED_WAITING`.
|
||||
|
||||
```java
|
||||
public class SimpleRunnable implements Runnable{
|
||||
@Override
|
||||
public void run() {
|
||||
try{
|
||||
Thread.sleep(5000);
|
||||
}
|
||||
catch(InterruptedException e){
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
In Main, if you check the state of T1 after 2s it will be `TIMED WAITING`
|
||||
```java
|
||||
public class Main {
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
Thread t1 = new Thread(new SimpleRunnable());
|
||||
t1.start();
|
||||
|
||||
Thread.sleep(2000);
|
||||
System.out.println(t1.getState());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 6. TERMINATED
|
||||
This is the state of a dead thread. It’s in the `TERMINATED` state when it has either finished execution or was terminated abnormally. There are different ways of terminating a thread.
|
||||
|
||||
Let’s try to achieve this state in the following example:
|
||||
```java
|
||||
public class TerminatedState implements Runnable {
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
Thread t1 = new Thread(new TerminatedState());
|
||||
t1.start();
|
||||
|
||||
// The following sleep method will give enough time for
|
||||
// thread t1 to complete
|
||||
Thread.sleep(1000);
|
||||
System.out.println(t1.getState());
|
||||
}
|
||||
|
||||
@Override
|
||||
public void run() {
|
||||
// No processing in this block
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
Here, while we’ve started thread t1, the very next statement Thread.sleep(1000) gives enough time for t1 to complete and so this program gives us the output as:
|
||||
```
|
||||
TERMINATED
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
54
Non-DSA Notes/LLD1 Notes/Miscellaneous Topics/Volatile.md
Normal file
54
Non-DSA Notes/LLD1 Notes/Miscellaneous Topics/Volatile.md
Normal file
@@ -0,0 +1,54 @@
|
||||
# Volatile Keyword
|
||||
---
|
||||
|
||||
## Recap of Basics
|
||||
- Interleaving: When threads start and pause, in the same blocks as other threads, this is called interleaving.
|
||||
- The execution of multiple threads happens in arbitrary order. The order in which threads execute can't be guranteed.
|
||||
|
||||
## Atomic Action
|
||||
An action that effectively happens all at once - either it happens completely or doesn't happen at all.
|
||||
|
||||
Even increments and decrements aren't atomic, nor are all primitive assignments.
|
||||
Example - Long and double assignments may not be atomic on all virtual machines.
|
||||
|
||||
## Thread Safe Code
|
||||
An object or a block of code is thread-safe, if it is not comprised by execution of concurrent threads.
|
||||
This means the correctness and consistency of program's output or its visible state, is unaffected by other threads.
|
||||
Atomic Operations and immutable objects are examples of thread-safe code.
|
||||
|
||||
In real life, there are shared resources which are available to multiple concurrent threads in real time. We have techniques, to control acess to the resources to prevent affects of interleaving threads. These technicques are -
|
||||
1) Synchronisation/Locking
|
||||
2) Volatile Keyword
|
||||
|
||||
### Problem 1 - Atomicity/Synchronization
|
||||
... alreaedy seen ...
|
||||
|
||||
|
||||
### Problem 2 - Memory Inconsistency Errors, Data Races
|
||||
The Operating system may read from heap variables, and make a copy of the value in each thread's own storage. Each threads has its own small and fast memory storage, that holds its own copy of shared resource's value.
|
||||
|
||||
Once thread can modify a shared variable, but this change might not be immediately reflected or visible. Instead it is first update in thread's local cache. The operating system may not flush the first thread's changes to the heap, until the thread has finished executing, causing memory inconsistency errors.
|
||||
|
||||
### Solution - Volatile Keyword
|
||||
- The volatile keyword is used as modifier for class variables.
|
||||
- It's an indicator that this variable's value may be changed by multiple threads.
|
||||
- This modifier ensures that the variable is always read from, and written to the main memory, rather than from any thread-specific cache.
|
||||
- This provides memory consistency for this variables value across threads.
|
||||
Volatile doesn't gurantee atomicicty.
|
||||
|
||||
However, volatile does not provide atomicity or synchronization, so additional synchronization mechanisms should be used in conjunction with it when necessary.
|
||||
|
||||
**When to use volatile**
|
||||
- When a variable is used to track the state of a shared resource, such as counter or a flag.
|
||||
- When a varaible is used to communicate between threads.
|
||||
|
||||
**When not use volatile**
|
||||
- When the variable is used by single thread.
|
||||
- When a variable is used to store a large amount of data.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user