mirror of
https://github.com/dholerobin/Lecture_Notes.git
synced 2025-09-18 13:00:28 +00:00
restructure again
This commit is contained in:
171
Dijkstra.md
171
Dijkstra.md
@@ -1,171 +0,0 @@
|
||||
Problem Statement
|
||||
--
|
||||
|
||||
Recently, Riya won the scholarship to attend the Linux Open Source Conference in Paris. She was very excited to be a part of it. On the day of the conference, she got late and now she wants to quickly know what's the shortest path she needs to follow in order to reach the conference venue as early as possible. She used google maps and luckily reached the venue on time. She was quite impressed by this app and wanted to build something like that herself but she wasn't sure how to find the shortes path from a source to destination in the most efficient way possible.
|
||||
Let's help Riya in finding this.
|
||||
|
||||
|
||||
Brute Force Solution
|
||||
--
|
||||
Ideally, the brute force solution to find the shortest path from a source node to the destination node can be to explore all possible paths and choose the one with the least node. But that will lead to exponential time complexity.
|
||||
|
||||
|
||||
Dijkstra Algorithm
|
||||
--
|
||||
|
||||
Specifically, given a graph G with non-negative weights, one can easily construct a new unweighted graph H (with the same vertices in G and some additional ones), by replacing each weighted edge with the number of edges equivalent to its weight.
|
||||
So, for example, if you have an edge (u,v) with weight 10 in G, we can replace this edge by a series of 10 edges between u and v (with new intermediate vertices ofcourse) in H. Now, the distances between the vertices that were originally from G is still preserved, and we've essentially converted the weighted graph into an unweighted graph that we can run BFS on.
|
||||
|
||||
At this point, one might realize that we don't really care about the distances to these new intermediate vertices, and you'd only want to enqueue/visit the vertices that were originally from G, which gets us to the idea of a priority queue.
|
||||
|
||||
So basically, we want to find the shortest path in between a source node and all other nodes (or a destination node), but we don’t want to have to check EVERY single possible source-to-destination combination to do this, because that would take a really long time for a large graph, and we would be checking a lot of paths which we should know aren’t correct! So we decide to take a _greedy_ approach!
|
||||
|
||||
Here when Dijkstra Algorithm come to our rescue!
|
||||
|
||||
**Dijkstra’s algorithm** is an **algorithm** that maps the shortest path between two nodes on a graph.
|
||||
|
||||
The best example to depict the application of Dijkstra’s algorithm is *Google Maps*. It gives you number of ways from one destination to the other. But, it primarily focuses on the shortest path between the 2 places.
|
||||
|
||||
**_Dijkstra’s algorithm_** can be used to determine the shortest path from one node in a graph to _every other node_ within the same graph data structure, provided that the nodes are reachable from the starting node.!
|
||||
|
||||
|
||||
**NOT SURE TO INCLUDE IT OR NOT**
|
||||
*Dijkstra’s algorithm follows somehow the principle of Dynamic Programming as well. Consider the shortest path from s to some vertex w. It traverses a sequence of vertices, with a final vertex v that then connects to w to finish the shortest path to w. The key observation is that the path up to v must be a shortest path to v. Because if it weren't, we could replace that path to v with a shorter path, which would also shorten the path to w, which would contradict the claim that we have a shortest path to w. Dijkstra's algorithm was that it is basically an efficient version of breadth-first search on a different graph.*
|
||||
|
||||
|
||||
Algorithm
|
||||
--
|
||||
Let's take a quick look at the steps and rules for running Dijkstra Algorithm.
|
||||
|
||||
|
||||
- We have a weighted graph `G` with a set of vertices (nodes) `V` and a set of edges `E`
|
||||
- We also have a starting node called `s`, and we set the distance between `s` and `s` to 0
|
||||
- Mark the distance between `s` and every other node as infinite, i.e. start the algorithm as if no node was reachable from node `s`
|
||||
- Mark all nodes (other than `s`) as unvisited, or mark `s` as visited if all other nodes are already marked as unvisited (which is the approach we'll use)
|
||||
- As long as there is an unvisited node, do the following:
|
||||
- Find the node `n` that has the shortest distance from the starting node `s`
|
||||
- Mark `n` as visited
|
||||
- For every edge between `n` and `m`, where `m` is unvisited:
|
||||
- If `smallestPath(s,n)` + `smallestPath(n,m)` < `smallestPath(s,m)`, update the cheapest path between `s` and `m` to equal `smallestPath(s,n)` + `smallestPath(n,m)`
|
||||
-
|
||||
These instructions are our golden rules that we will always follow, until our algorithm is done running. So, let’s get to it!
|
||||
|
||||
This might seem complicated but let's go through an **example** that makes this a bit more intuitive::
|
||||
|
||||
|
||||
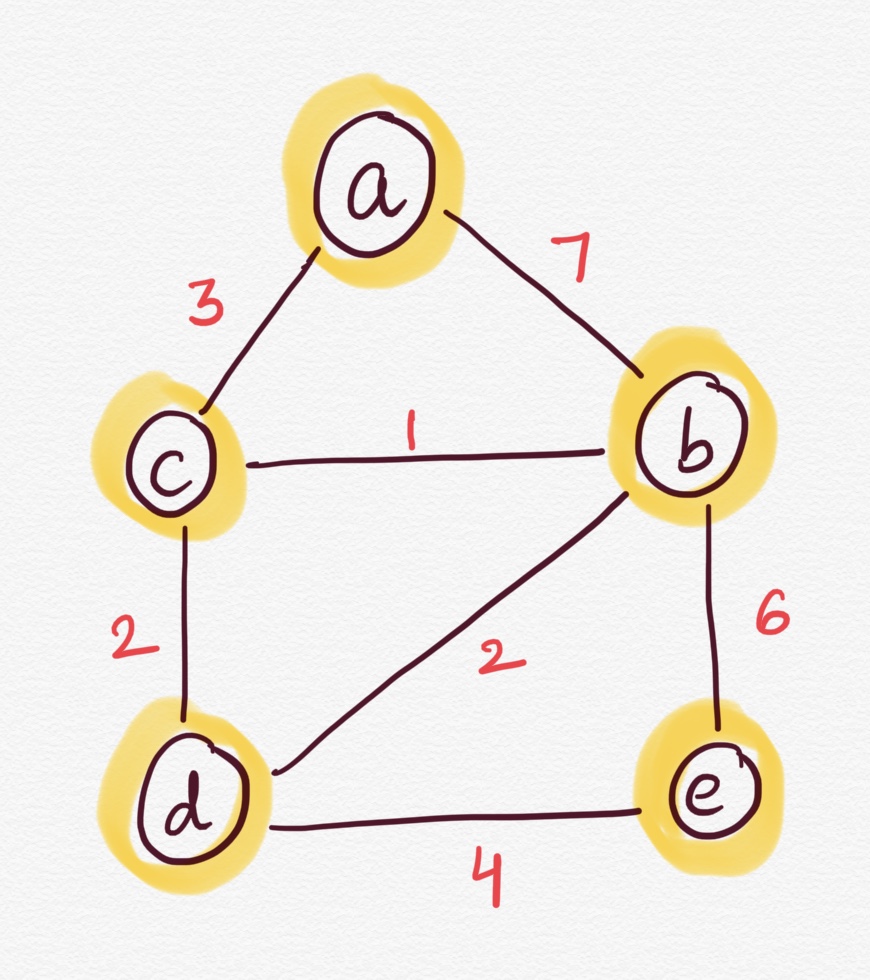
Consider the weighted and undirected graph above.
|
||||
We're looking for the shortest path from node `a` to node `e`.
|
||||
|
||||
|
||||
|
||||
|
||||
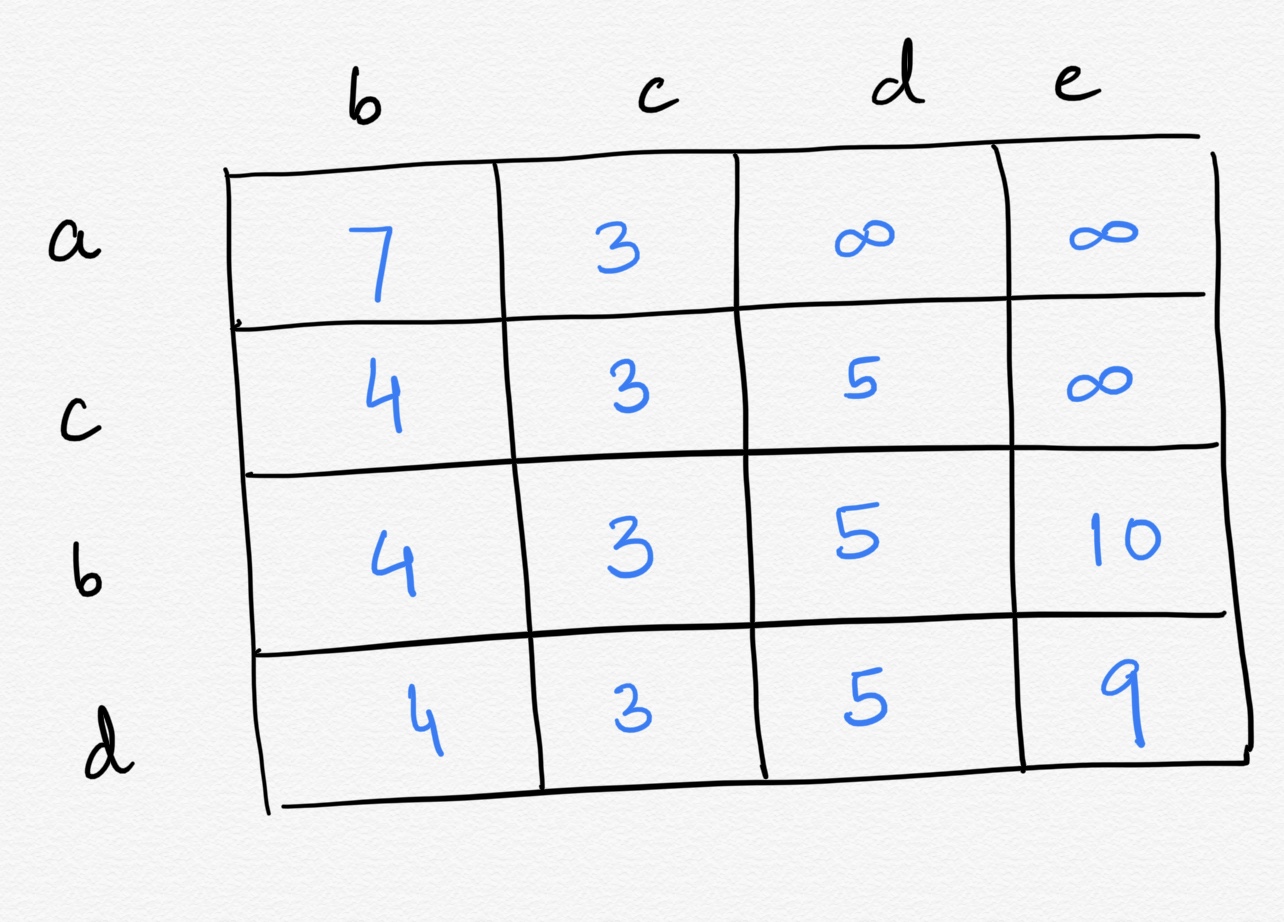
We'll be using a table to better represent the algorithm and understand what is going on.
|
||||
- In the beginning, we'll determine the edge weights of `a` from its adjacent nodes. The rest of the distances are denoted as positive infinity, i.e. they are not reachable from any of the nodes we've processed so far.
|
||||
- The next step is to find the closest node that hasn't been visited yet that we can actually reach from one of the nodes we've processed. In our case, this is node `c` [shortest distance] and we'll mark node `a` as visited.
|
||||
- We see that from node `c` we can reach nodes `b` and `d`.
|
||||
- node `b` -> to get from `c` to `b` costs 1 units, given that the shortest path from `a` to `c` costs 3 units, 3 + 1 is less than 7 (the shortest path between `a` and `b`). This means we have found a better path from `a` to `b` through the node `c`, so we update that cell in the table.
|
||||
- node `d` -> to get from `c` to `d` costs 2 units, and since `d` was previously unreachable, 3 + 2 is definitely better than infinity so we update that particular cell in the table.
|
||||
|
||||
- We now have choose between node `b` and node `d`, since node `b` has shortest distance between the both of them, we choose node `b`.
|
||||
- Unvisited, reachable nodes from node `b` are nodes `d` and `e`:
|
||||
- node `d` -> it costs 2 units to get from node `b` to node `d`, and 4 + 2 isn't better than the previous 5 unit value we found, so there's no need to update.
|
||||
- node `e` -> to get from `b` to `e` costs 6 units, and since `e` was previously unreachable, 4 + 6 is definitely better than infinity so we update that particular cell in the table.
|
||||
- Mark node `b` as visited.
|
||||
|
||||
- The next node to be considered is node `d`.
|
||||
- Unvisited, reachable nodes from node `d` is node `e`:
|
||||
- node `e` -> to get from `d` to `e` costs 4 units, given that the shortest path from `a` to `d` costs 5 units, 5 + 4 is less than 10. This means we have found a better path from `a` to `e` through the node `d`, so we update that cell in the table.
|
||||
|
||||
|
||||
- Since the next closest, reachable, unvisited node is our end node - the algorithm is over and we have our result - the value of the shortest path between `a` and `e` is 9.
|
||||
|
||||
Pseudocode
|
||||
--
|
||||
|
||||
```
|
||||
def dijkstra(self, source, dest):
|
||||
assert source in self.vertices, 'Such source node doesn't exist'
|
||||
|
||||
# 1. Mark all nodes unvisited and store them.
|
||||
# 2. Set the distance to zero for our initial node
|
||||
# and to infinity for other nodes.
|
||||
distances = {vertex: inf for vertex in self.vertices}
|
||||
previous_vertices = {
|
||||
vertex: None for vertex in self.vertices
|
||||
}
|
||||
distances[source] = 0
|
||||
vertices = self.vertices.copy()
|
||||
|
||||
while vertices:
|
||||
# 3. Select the unvisited node with the smallest distance,
|
||||
# it's current node now.
|
||||
current_vertex = min(
|
||||
vertices, key=lambda vertex: distances[vertex])
|
||||
|
||||
# 6. Stop, if the smallest distance
|
||||
# among the unvisited nodes is infinity.
|
||||
if distances[current_vertex] == inf:
|
||||
break
|
||||
|
||||
# 4. Find unvisited neighbors for the current node
|
||||
# and calculate their distances through the current node.
|
||||
for neighbour, cost in self.neighbours[current_vertex]:
|
||||
alternative_route = distances[current_vertex] + cost
|
||||
|
||||
# Compare the newly calculated distance to the assigned
|
||||
# and save the smaller one.
|
||||
if alternative_route < distances[neighbour]:
|
||||
distances[neighbour] = alternative_route
|
||||
previous_vertices[neighbour] = current_vertex
|
||||
|
||||
# 5. Mark the current node as visited
|
||||
# and remove it from the unvisited set.
|
||||
vertices.remove(current_vertex)
|
||||
|
||||
|
||||
path, current_vertex = deque(), dest
|
||||
while previous_vertices[current_vertex] is not None:
|
||||
path.appendleft(current_vertex)
|
||||
current_vertex = previous_vertices[current_vertex]
|
||||
if path:
|
||||
path.appendleft(current_vertex)
|
||||
return path
|
||||
```
|
||||
|
||||
Time Complexity
|
||||
--
|
||||
|
||||
Now let's calculate the running time of Dijkstra's algorithm using a min-heap priority queue.
|
||||
|
||||
- It takes O(|V|) time to construct the initial priority queue of |V| vertices .
|
||||
- Each of the subsequent priority queue operations takes time O(log q) where q is the current size of the queue.
|
||||
- Each vertex u is deleted from the queue exactly once, after it has obtained its least cost path from the source vertex.
|
||||
- After u is deleted from the queue, each neighbor v of vertex u is tested to see if the path from the source to v through u has a lower cost than the current path from the source to v.
|
||||
- If a lower cost path is obtained through u, then the path cost for v is decreased, and the vertex priority changed in the queue.
|
||||
- So, the test for improving a path is performed a total of O(|E|) times with a worst-case time of O(log |V|) to update the vertex priority for each test.
|
||||
|
||||
Consequently, the algorithm runs in time **O(|E| log |V|)**.
|
||||
|
||||
|
||||
Problems with Dijkstra
|
||||
--
|
||||
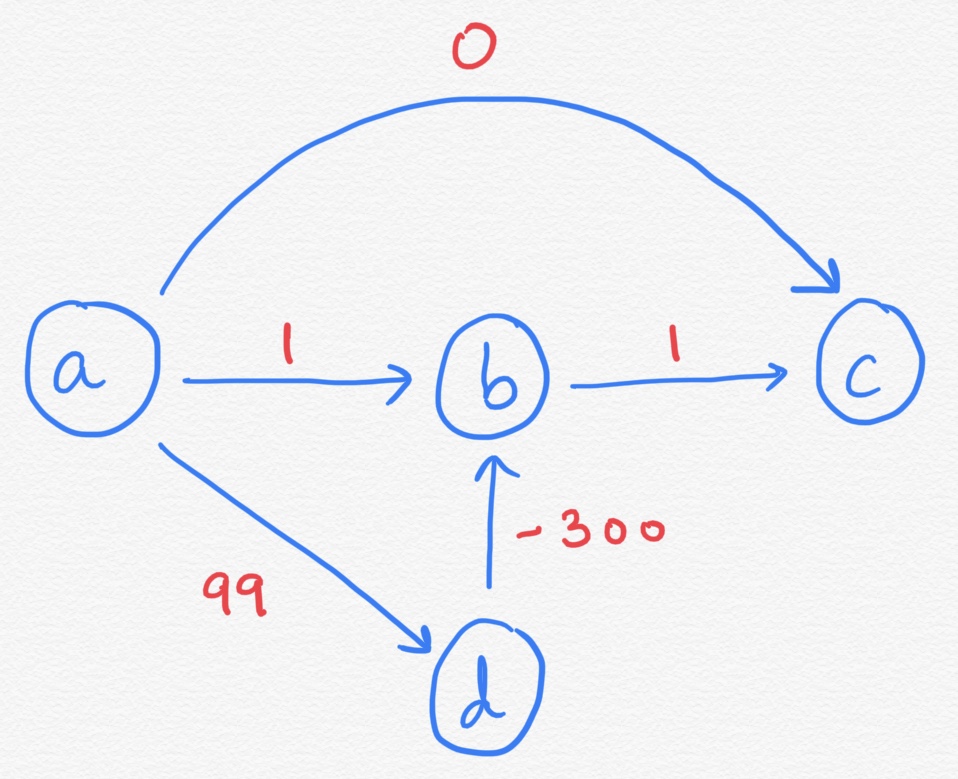
DjkstraDijkstra algorithm does not work with graphs having negative weight edges. The graph shown below is a good example to understand this.
|
||||
|
||||
|
||||
|
||||
|
||||
Dijkstra follows a simple rule that if all edges have non negative weights, adding an edge will never make the path smaller. That's why it follows the greedy strategy and picks up the shortest path to find the optimal solution.
|
||||
|
||||
If we ran the algorithm, looking for the least expensive path between **a** and **c**, the algorithm would return 0 even though that's not correct (the least expensive cost is -200).
|
||||
Let's start with the node **a**.
|
||||
- The path from **a** to **a** (a -> a) will be marked 0 and everything else will be marked infinity.
|
||||
- In the next turn
|
||||
- **a** -> **b** will be 1.
|
||||
- **a** -> **d** will be 99.
|
||||
- **a** -> **c** will be 0.
|
||||
|
||||
Note that, there will be no changes if you expand vertices **b** and **c**.
|
||||
When you expand **d**, the path from **a** to **b** will be changed to -201.
|
||||
Notice that **a** -> **c** is still 0, when there is a shorter path **a** -> **d** -> **b** -> **c** costing -200.
|
||||
|
||||
But, Dijsktra will not be able to find out this and will subsequently fails in this case.
|
||||
@@ -1,374 +1,171 @@
|
||||
<script type="text/javascript" src="https://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS_HTML"></script>
|
||||
Problem Statement
|
||||
--
|
||||
|
||||
Recently, Riya won the scholarship to attend the Linux Open Source Conference in Paris. She was very excited to be a part of it. On the day of the conference, she got late and now she wants to quickly know what's the shortest path she needs to follow in order to reach the conference venue as early as possible. She used google maps and luckily reached the venue on time. She was quite impressed by this app and wanted to build something like that herself but she wasn't sure how to find the shortes path from a source to destination in the most efficient way possible.
|
||||
Let's help Riya in finding this.
|
||||
|
||||
|
||||
## Dijkstra's Algorithm
|
||||
|
||||
Have you ever used Google Maps?
|
||||
|
||||
Ever wondered how it works? How does it tell you the shortest path from point A to B?
|
||||
|
||||
At the backside of it, they are using something known as "Shortest Path Finding algorithm". Well, what does the shortest path actually mean?
|
||||
|
||||
The **dark** line represents the shortest path from the home to the office, in the diagram below
|
||||

|
||||
|
||||
Do you know how to represent the roads between different places? This is **Weighted Directed Graph** - a directed graph with edges having weights.
|
||||
|
||||
## Quiz Time:
|
||||
|
||||
Now can you find the shortest path from the source vertex to the target vertex in the image below?
|
||||
|
||||

|
||||
|
||||
Answer: The dark line shows the answer.
|
||||
|
||||

|
||||
|
||||
-- --
|
||||
Single Source Shortest Path problem (SSSP)
|
||||
-----------------------------
|
||||
**Statement**: Given a graph find out the shortest path from a given point to all other points.
|
||||
|
||||
### How to solve this problem?
|
||||
When we talk about the graph we have two standard techniques to traverse: DFS and BFS.
|
||||
|
||||
Can you solve this problem using these standard algorithms?
|
||||
|
||||
Certainly. We will see how to find the shortest path from the source to the destination using DFS.
|
||||
|
||||
Let's look at how can we solve it using DFS.
|
||||
Brute Force Solution
|
||||
--
|
||||
Ideally, the brute force solution to find the shortest path from a source node to the destination node can be to explore all possible paths and choose the one with the least node. But that will lead to exponential time complexity.
|
||||
|
||||
|
||||
### Solution using DFS:
|
||||
Dijkstra Algorithm
|
||||
--
|
||||
|
||||
**Algorithm:** DFS approach is very simple.
|
||||
Specifically, given a graph G with non-negative weights, one can easily construct a new unweighted graph H (with the same vertices in G and some additional ones), by replacing each weighted edge with the number of edges equivalent to its weight.
|
||||
So, for example, if you have an edge (u,v) with weight 10 in G, we can replace this edge by a series of 10 edges between u and v (with new intermediate vertices ofcourse) in H. Now, the distances between the vertices that were originally from G is still preserved, and we've essentially converted the weighted graph into an unweighted graph that we can run BFS on.
|
||||
|
||||
- Start from the source vertex
|
||||
- Explore all the vertices adjacent to the source vertex
|
||||
- For each adjacent vertex, If it satisfies the relaxation condition then update the new distance and parent vertex
|
||||
- Then recurse on it, by considering itself as the new source.
|
||||
At this point, one might realize that we don't really care about the distances to these new intermediate vertices, and you'd only want to enqueue/visit the vertices that were originally from G, which gets us to the idea of a priority queue.
|
||||
|
||||
**Relaxation** means if you reach the vertex with less distance than encountered before, then update the data. **Parent vertex** means the vertex by which the particular vertex is reached.
|
||||
So basically, we want to find the shortest path in between a source node and all other nodes (or a destination node), but we don’t want to have to check EVERY single possible source-to-destination combination to do this, because that would take a really long time for a large graph, and we would be checking a lot of paths which we should know aren’t correct! So we decide to take a _greedy_ approach!
|
||||
|
||||
This way DFS will explore all the possible paths from the source vertex to the destination vertex and will find out the shortest path.
|
||||
Here when Dijkstra Algorithm come to our rescue!
|
||||
|
||||
Here in the code, we will represent the graph using adjacency list representation:
|
||||
**Dijkstra’s algorithm** is an **algorithm** that maps the shortest path between two nodes on a graph.
|
||||
|
||||
```c++
|
||||
#include <bits/stdc++.h>
|
||||
using namespace std;
|
||||
#define MAX_DIST 100000000
|
||||
|
||||
// Function to print the required path
|
||||
void printpath(vector<int>& parent, int vertex, int source, int destination)
|
||||
{
|
||||
if(vertex == source)
|
||||
{
|
||||
cout << source << "-->";
|
||||
return;
|
||||
}
|
||||
printpath(parent, parent[vertex], source, destination);
|
||||
cout << vertex << (vertex==destination ? "\n" : "-->");
|
||||
}
|
||||
|
||||
void DFS(int source, int destination, vector<vector<pair<int,int> > > &graph, vector<int> &distances, vector<int> &parent)
|
||||
{
|
||||
// When we reach at the destination just return
|
||||
if(source == destination)
|
||||
return;
|
||||
|
||||
// Do DFS over all the vertices connected
|
||||
// with the source vertex
|
||||
for(auto vertex: graph[source])
|
||||
{
|
||||
// Relaxation of edge:
|
||||
// If the distance is less than what we
|
||||
// have encountered uptil now then update
|
||||
// Distance and Parent vertex
|
||||
if(distances[vertex.second] > distances[source] + vertex.first)
|
||||
{
|
||||
distances[vertex.second] = distances[source] + vertex.first;
|
||||
parent[vertex.second] = source;
|
||||
}
|
||||
|
||||
// Do DFS over all the vertices connected
|
||||
// with the source vertex
|
||||
DFS(vertex.second, destination, graph, distances, parent);
|
||||
}
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
// Number of vertices in graph
|
||||
int n = 6;
|
||||
|
||||
// Adjacency list representation of the
|
||||
// Directed Graph
|
||||
vector<vector<pair<int, int> > > graph;
|
||||
|
||||
graph.assign(n + 1, vector<pair<int, int> >());
|
||||
|
||||
// Now make the Directed Graph
|
||||
// Note that edges are
|
||||
// in the form (weight, vertex ID)
|
||||
graph[1].push_back( make_pair(1, 2) );
|
||||
graph[1].push_back( make_pair(6, 2) );
|
||||
graph[2].push_back( make_pair(1, 4) );
|
||||
graph[4].push_back( make_pair(1, 3) );
|
||||
graph[3].push_back( make_pair(1, 5) );
|
||||
graph[2].push_back( make_pair(7, 5) );
|
||||
graph[4].push_back( make_pair(3, 6) );
|
||||
|
||||
// Array to store the distances
|
||||
vector<int> distances(n+1, MAX_DIST);
|
||||
|
||||
// Array to store the parent vertices
|
||||
vector<int> parent(n+1, -1);
|
||||
|
||||
int source = 1, destination = 5;
|
||||
|
||||
distances[source] = 0;
|
||||
|
||||
// Do DFS
|
||||
DFS(source, destination, graph, distances, parent);
|
||||
|
||||
int shortest_distance = distances[destination];
|
||||
|
||||
// To print shortest_distance
|
||||
cout << shortest_distance << endl;
|
||||
|
||||
// To print the path of the shortest_distance
|
||||
printpath(parent, destination, source, destination);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
### Time Complexity of DFS
|
||||
As DFS explores all possible paths from the given source vertex to the destination vertex, this may lead to exponential time complexity in a very dense graph.
|
||||
|
||||
So, our DFS approach is not efficient. What next?
|
||||
|
||||
We have a very interesting and elegant algorithm to solve the problem named " **Dijkstra's Algorithm**". This is the algorithm whose variants are used by most of the path finding applications.
|
||||
|
||||
## Dijkstra's Algorithm:
|
||||
|
||||
Dijkstra's Algorithm solves SSSP.
|
||||
|
||||
Dijkstra's Algorithm is an iterative algorithm similar to **BFS**, but here we have a little twist.
|
||||
|
||||
**Algorithm:**
|
||||
|
||||
1. Mark the distance between the source and all other vertices to $\infty$ and assign all the parent vertices to some sentinel (not used value).
|
||||
2. The set is a collection of vertices which is empty at the start of the algorithm.
|
||||
3. Set the distance between source to source as 0 and add the source vertex to the set.
|
||||
4. Find the minimum distance vertex from the set and erase it from the set. Mark it as processed. let this vertex be $A$.
|
||||
5. Explore all the edges connected to $A$.
|
||||
6. If the edge is connected to the unprocessed vertex and it satisfies the relaxation condition below, then relax that edge and insert the vertex into the set.
|
||||
**Relaxation Condition:** Let the edge be $A-u$,
|
||||
$$\text{Distance}[u] < \text{Distance}[A] + \text{EdgeWeight}(A,u)$$
|
||||
4. If the set is empty, then stop the algorithm.
|
||||
5. Otherwise, repeat from step 3.
|
||||
The best example to depict the application of Dijkstra’s algorithm is *Google Maps*. It gives you number of ways from one destination to the other. But, it primarily focuses on the shortest path between the 2 places.
|
||||
|
||||
In Dijkstra's Algorithm, we explore the vertices in the way BFS does, however here we have to find the minimum distance vertex from the set.
|
||||
|
||||
Which data structure can help us find the minimum distance vertex from the set?
|
||||
|
||||
**Priority Queue** is the data structure which achieves this goal in an efficient manner $\mathcal{O}(\log n)$.
|
||||
|
||||
**Visualization:**
|
||||
|
||||
- Here cloud represents the processed nodes - the nodes whose final shortest distance is found.
|
||||
- Solid lines represent the edges that are discovered.
|
||||
- Numbers in square brackets represent the current distance of that vertex from the source vertex.
|
||||
**_Dijkstra’s algorithm_** can be used to determine the shortest path from one node in a graph to _every other node_ within the same graph data structure, provided that the nodes are reachable from the starting node.!
|
||||
|
||||
|
||||
1. Start from the source vertex 1. 
|
||||
2. Vertex 1 discovers vertices 2 and 3. It consequently does the relaxation and adds vertices 2 and 3 in the set.
|
||||

|
||||
3. The minimum distance vertex in the set is vertex 2. So vertex 2 will be the next source vertex.
|
||||
|
||||
It will discover vertices 5 and 4.
|
||||
|
||||
Now vertex 2 is added to the cloud as it is processed.
|
||||

|
||||
4. The next minimum distance vertex is vertex 4.
|
||||
It relaxes both 3 and 6. Then vertex 4 will be added to the cloud.
|
||||

|
||||
5. Next vertex will be 3. It relaxes 5.
|
||||

|
||||
6. Now there will not be any more relaxations.
|
||||
All the vertices in the priority queue will dequeue without adding any new vertex to the set.
|
||||

|
||||
|
||||
Now we have found the shortest distances to all the vertices from the given source vertex.
|
||||
|
||||
We can use parent array to store parent of the given vertex, and then we can find out the shortest path for any vertex.
|
||||
|
||||
```c++
|
||||
#include <bits/stdc++.h>
|
||||
using namespace std;
|
||||
#define MAX_DIST 100000000
|
||||
|
||||
// Function to print the required path
|
||||
void printpath(vector<int>& parent, int vertex, int source, int destination)
|
||||
{
|
||||
if(vertex == source)
|
||||
{
|
||||
cout << source << "-->";
|
||||
return;
|
||||
}
|
||||
printpath(parent, parent[vertex], source, destination);
|
||||
|
||||
cout << vertex << (vertex==destination ? "\n" : "-->");
|
||||
}
|
||||
**NOT SURE TO INCLUDE IT OR NOT**
|
||||
*Dijkstra’s algorithm follows somehow the principle of Dynamic Programming as well. Consider the shortest path from s to some vertex w. It traverses a sequence of vertices, with a final vertex v that then connects to w to finish the shortest path to w. The key observation is that the path up to v must be a shortest path to v. Because if it weren't, we could replace that path to v with a shorter path, which would also shorten the path to w, which would contradict the claim that we have a shortest path to w. Dijkstra's algorithm was that it is basically an efficient version of breadth-first search on a different graph.*
|
||||
|
||||
|
||||
// Dijkstra's Algorithm
|
||||
int Dijkstra_Algo(vector<vector<pair<int, int> > >& Graph,
|
||||
int src, int target, vector<int> & distances, vector<int> & parent)
|
||||
{
|
||||
|
||||
// Minimum Priority Queue to keep track of the discovered
|
||||
// vertex which has the minimum distance
|
||||
priority_queue<pair<int, int>, vector<pair<int, int> >,
|
||||
greater<pair<int, int> > > container;
|
||||
|
||||
// To check whether vertex is in the cloud
|
||||
vector<bool> processed(Graph.size());
|
||||
|
||||
// Start with source vertex
|
||||
// Push the source vertex in the
|
||||
// Priority Queue
|
||||
container.push(make_pair(0, src));
|
||||
|
||||
// Assign distance to source as 0
|
||||
distances[src] = 0;
|
||||
|
||||
|
||||
while (!container.empty()) {
|
||||
|
||||
// Pop the least distance vertex from the Priority Queue
|
||||
pair<int, int> temp = container.top();
|
||||
int current_src = temp.second;
|
||||
|
||||
// Pop the minimum distance vertex
|
||||
container.pop();
|
||||
|
||||
processed[current_src] = true;
|
||||
// current source vertex
|
||||
for (auto vertex : Graph[current_src]) {
|
||||
|
||||
// Distance of the vertex from its
|
||||
// temporary source vertex
|
||||
int distance = distances[current_src] + vertex.first;
|
||||
Algorithm
|
||||
--
|
||||
Let's take a quick look at the steps and rules for running Dijkstra Algorithm.
|
||||
|
||||
// Relaxation of edge
|
||||
if (!processed[vertex.second] && distance < distances[vertex.second]) {
|
||||
|
||||
// Updating the distance
|
||||
distances[vertex.second] = distance;
|
||||
- We have a weighted graph `G` with a set of vertices (nodes) `V` and a set of edges `E`
|
||||
- We also have a starting node called `s`, and we set the distance between `s` and `s` to 0
|
||||
- Mark the distance between `s` and every other node as infinite, i.e. start the algorithm as if no node was reachable from node `s`
|
||||
- Mark all nodes (other than `s`) as unvisited, or mark `s` as visited if all other nodes are already marked as unvisited (which is the approach we'll use)
|
||||
- As long as there is an unvisited node, do the following:
|
||||
- Find the node `n` that has the shortest distance from the starting node `s`
|
||||
- Mark `n` as visited
|
||||
- For every edge between `n` and `m`, where `m` is unvisited:
|
||||
- If `smallestPath(s,n)` + `smallestPath(n,m)` < `smallestPath(s,m)`, update the cheapest path between `s` and `m` to equal `smallestPath(s,n)` + `smallestPath(n,m)`
|
||||
-
|
||||
These instructions are our golden rules that we will always follow, until our algorithm is done running. So, let’s get to it!
|
||||
|
||||
// Updating the parent vertex
|
||||
parent[vertex.second] = current_src;
|
||||
|
||||
// Adding the relaxed edge in the prority queue
|
||||
container.push(make_pair(distance, vertex.second));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// return the shortest distance
|
||||
return distances[target];
|
||||
}
|
||||
int main()
|
||||
{
|
||||
// Number of vertices in graph
|
||||
int n = 6;
|
||||
|
||||
// Adjacency list representation of the
|
||||
// Directed Graph
|
||||
vector<vector<pair<int, int> > > graph;
|
||||
|
||||
graph.assign(n + 1, vector<pair<int, int> >());
|
||||
This might seem complicated but let's go through an **example** that makes this a bit more intuitive::
|
||||
|
||||
// Now make the Directed Graph
|
||||
// Note that edges are
|
||||
// in the form (weight, vertex ID)
|
||||
graph[1].push_back( make_pair(1, 2) );
|
||||
graph[1].push_back( make_pair(6, 2) );
|
||||
graph[2].push_back( make_pair(1, 4) );
|
||||
graph[4].push_back( make_pair(1, 3) );
|
||||
graph[3].push_back( make_pair(1, 5) );
|
||||
graph[2].push_back( make_pair(7, 5) );
|
||||
graph[4].push_back( make_pair(3, 6) );
|
||||
|
||||
// Array to store the distances
|
||||
vector<int> distances(n+1, MAX_DIST);
|
||||
|
||||
// Array to store the parent vertices
|
||||
vector<int> parent(n+1, -1);
|
||||
|
||||
// For example destination is taken as 5
|
||||
int source = 1, destination = 5;
|
||||
|
||||
distances[source] = 0;
|
||||
|
||||
// Dijkstra's algorithm
|
||||
int shortest_distance = Dijkstra_Algo(graph, source, destination, distances, parent);
|
||||
|
||||
// To print shortest_distance
|
||||
cout << shortest_distance << endl;
|
||||
|
||||
// To print the path of the shortest_distance
|
||||
printpath(parent, destination, source, destination);
|
||||
|
||||
return 0;
|
||||

|
||||
Consider the weighted and undirected graph above.
|
||||
We're looking for the shortest path from node `a` to node `e`.
|
||||
|
||||
}
|
||||
|
||||

|
||||
|
||||
We'll be using a table to better represent the algorithm and understand what is going on.
|
||||
- In the beginning, we'll determine the edge weights of `a` from its adjacent nodes. The rest of the distances are denoted as positive infinity, i.e. they are not reachable from any of the nodes we've processed so far.
|
||||
- The next step is to find the closest node that hasn't been visited yet that we can actually reach from one of the nodes we've processed. In our case, this is node `c` [shortest distance] and we'll mark node `a` as visited.
|
||||
- We see that from node `c` we can reach nodes `b` and `d`.
|
||||
- node `b` -> to get from `c` to `b` costs 1 units, given that the shortest path from `a` to `c` costs 3 units, 3 + 1 is less than 7 (the shortest path between `a` and `b`). This means we have found a better path from `a` to `b` through the node `c`, so we update that cell in the table.
|
||||
- node `d` -> to get from `c` to `d` costs 2 units, and since `d` was previously unreachable, 3 + 2 is definitely better than infinity so we update that particular cell in the table.
|
||||
|
||||
- We now have choose between node `b` and node `d`, since node `b` has shortest distance between the both of them, we choose node `b`.
|
||||
- Unvisited, reachable nodes from node `b` are nodes `d` and `e`:
|
||||
- node `d` -> it costs 2 units to get from node `b` to node `d`, and 4 + 2 isn't better than the previous 5 unit value we found, so there's no need to update.
|
||||
- node `e` -> to get from `b` to `e` costs 6 units, and since `e` was previously unreachable, 4 + 6 is definitely better than infinity so we update that particular cell in the table.
|
||||
- Mark node `b` as visited.
|
||||
|
||||
- The next node to be considered is node `d`.
|
||||
- Unvisited, reachable nodes from node `d` is node `e`:
|
||||
- node `e` -> to get from `d` to `e` costs 4 units, given that the shortest path from `a` to `d` costs 5 units, 5 + 4 is less than 10. This means we have found a better path from `a` to `e` through the node `d`, so we update that cell in the table.
|
||||
|
||||
|
||||
- Since the next closest, reachable, unvisited node is our end node - the algorithm is over and we have our result - the value of the shortest path between `a` and `e` is 9.
|
||||
|
||||
Pseudocode
|
||||
--
|
||||
|
||||
```
|
||||
def dijkstra(self, source, dest):
|
||||
assert source in self.vertices, 'Such source node doesn't exist'
|
||||
|
||||
# 1. Mark all nodes unvisited and store them.
|
||||
# 2. Set the distance to zero for our initial node
|
||||
# and to infinity for other nodes.
|
||||
distances = {vertex: inf for vertex in self.vertices}
|
||||
previous_vertices = {
|
||||
vertex: None for vertex in self.vertices
|
||||
}
|
||||
distances[source] = 0
|
||||
vertices = self.vertices.copy()
|
||||
|
||||
while vertices:
|
||||
# 3. Select the unvisited node with the smallest distance,
|
||||
# it's current node now.
|
||||
current_vertex = min(
|
||||
vertices, key=lambda vertex: distances[vertex])
|
||||
|
||||
# 6. Stop, if the smallest distance
|
||||
# among the unvisited nodes is infinity.
|
||||
if distances[current_vertex] == inf:
|
||||
break
|
||||
|
||||
# 4. Find unvisited neighbors for the current node
|
||||
# and calculate their distances through the current node.
|
||||
for neighbour, cost in self.neighbours[current_vertex]:
|
||||
alternative_route = distances[current_vertex] + cost
|
||||
|
||||
# Compare the newly calculated distance to the assigned
|
||||
# and save the smaller one.
|
||||
if alternative_route < distances[neighbour]:
|
||||
distances[neighbour] = alternative_route
|
||||
previous_vertices[neighbour] = current_vertex
|
||||
|
||||
# 5. Mark the current node as visited
|
||||
# and remove it from the unvisited set.
|
||||
vertices.remove(current_vertex)
|
||||
|
||||
|
||||
path, current_vertex = deque(), dest
|
||||
while previous_vertices[current_vertex] is not None:
|
||||
path.appendleft(current_vertex)
|
||||
current_vertex = previous_vertices[current_vertex]
|
||||
if path:
|
||||
path.appendleft(current_vertex)
|
||||
return path
|
||||
```
|
||||
|
||||
## Time Complexity of Dijkstra's Algorithm:
|
||||
Time Complexity
|
||||
--
|
||||
|
||||
1. $\mathcal{O}(|E|)$ time to make the Weighted Directed Graph.
|
||||
2. $\mathcal{O}(|E| + |V|)$ can be taken by the while loop which is similar to BFS time complexity.
|
||||
3. $\mathcal{O}(\log |V|)$ time to insert the relaxed vertex in the priority queue.
|
||||
Now let's calculate the running time of Dijkstra's algorithm using a min-heap priority queue.
|
||||
|
||||
So the overall complexity of the Dijkstra's Algorithm will be
|
||||
$$\mathcal{O}((|E| + |V|) \times \log(|V|))$$
|
||||
- It takes O(|V|) time to construct the initial priority queue of |V| vertices .
|
||||
- Each of the subsequent priority queue operations takes time O(log q) where q is the current size of the queue.
|
||||
- Each vertex u is deleted from the queue exactly once, after it has obtained its least cost path from the source vertex.
|
||||
- After u is deleted from the queue, each neighbor v of vertex u is tested to see if the path from the source to v through u has a lower cost than the current path from the source to v.
|
||||
- If a lower cost path is obtained through u, then the path cost for v is decreased, and the vertex priority changed in the queue.
|
||||
- So, the test for improving a path is performed a total of O(|E|) times with a worst-case time of O(log |V|) to update the vertex priority for each test.
|
||||
|
||||
Here $|E|$ represents the number of edges in the graph and $|V|$ represents the number of vertices in the graph.
|
||||
Consequently, the algorithm runs in time **O(|E| log |V|)**.
|
||||
|
||||
|
||||
## Limitation of Dijkstra's Algorithm:
|
||||
|
||||
When there are negative weight edges in the graph, then Dijkstra's algorithm does not work.
|
||||
|
||||
Example:
|
||||

|
||||
|
||||
It will find the path from $a$ to $c$ incorrectly.
|
||||
|
||||
What if there is a negative cycle in the graph?
|
||||
|
||||
**Negative Cycle:** Cycle in which sum of the weights of the edges is negative.
|
||||
|
||||
When there is any negative cycle in the graph then Dijkstra's algorithm will run forever, because then we can reach the affected vertices in negative infinite cost.
|
||||
|
||||
Note that the graph, we have used, is connected. If you have a vertex which is not connected, then you cannot find the shortest distance to it!
|
||||
|
||||
## **Applications of Dijkstra's algorithm:**
|
||||
Problems with Dijkstra
|
||||
--
|
||||
DjkstraDijkstra algorithm does not work with graphs having negative weight edges. The graph shown below is a good example to understand this.
|
||||
|
||||
|
||||
1. One very famous variant is the "Widest Path Finding Algorithm", which is an algorithm to finding a path between two vertices of the graph **maximizing the weight of the minimum-weight edge in the path**.
|
||||

|
||||
|
||||
In the practical application, this problem can be seen as a graph with routers as its vertices and edges representing bandwidth between two vertices. Now if we want to find the maximum bandwidth path between two places in the internet connection, then this algorithm is useful which is highly based on Dijkstra's Algorithm.
|
||||
Dijkstra follows a simple rule that if all edges have non negative weights, adding an edge will never make the path smaller. That's why it follows the greedy strategy and picks up the shortest path to find the optimal solution.
|
||||
|
||||
2. A widely used application of the shortest path algorithm is in network routing protocols "Routing protocol".
|
||||
If we ran the algorithm, looking for the least expensive path between **a** and **c**, the algorithm would return 0 even though that's not correct (the least expensive cost is -200).
|
||||
Let's start with the node **a**.
|
||||
- The path from **a** to **a** (a -> a) will be marked 0 and everything else will be marked infinity.
|
||||
- In the next turn
|
||||
- **a** -> **b** will be 1.
|
||||
- **a** -> **d** will be 99.
|
||||
- **a** -> **c** will be 0.
|
||||
|
||||
## Other Shortest Path Finding Algorithms:
|
||||
|
||||
1 Bellman-Ford Algorithm
|
||||
2. Using Dynamic Programming
|
||||
3. All Pair Shortest Path Algorithm - **Floyd-Warshall Algorithm**, which finds the shortest path between every pair of vertices.
|
||||
Note that, there will be no changes if you expand vertices **b** and **c**.
|
||||
When you expand **d**, the path from **a** to **b** will be changed to -201.
|
||||
Notice that **a** -> **c** is still 0, when there is a shorter path **a** -> **d** -> **b** -> **c** costing -200.
|
||||
|
||||
But, Dijsktra will not be able to find out this and will subsequently fails in this case.
|
||||
|
||||
374
articles/Akash Articles/rendered/Dijkstra.html
Normal file
374
articles/Akash Articles/rendered/Dijkstra.html
Normal file
@@ -0,0 +1,374 @@
|
||||
<script type="text/javascript" src="https://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS_HTML"></script>
|
||||
|
||||
|
||||
## Dijkstra's Algorithm
|
||||
|
||||
Have you ever used Google Maps?
|
||||
|
||||
Ever wondered how it works? How does it tell you the shortest path from point A to B?
|
||||
|
||||
At the backside of it, they are using something known as "Shortest Path Finding algorithm". Well, what does the shortest path actually mean?
|
||||
|
||||
The **dark** line represents the shortest path from the home to the office, in the diagram below
|
||||

|
||||
|
||||
Do you know how to represent the roads between different places? This is **Weighted Directed Graph** - a directed graph with edges having weights.
|
||||
|
||||
## Quiz Time:
|
||||
|
||||
Now can you find the shortest path from the source vertex to the target vertex in the image below?
|
||||
|
||||

|
||||
|
||||
Answer: The dark line shows the answer.
|
||||
|
||||

|
||||
|
||||
-- --
|
||||
Single Source Shortest Path problem (SSSP)
|
||||
-----------------------------
|
||||
**Statement**: Given a graph find out the shortest path from a given point to all other points.
|
||||
|
||||
### How to solve this problem?
|
||||
When we talk about the graph we have two standard techniques to traverse: DFS and BFS.
|
||||
|
||||
Can you solve this problem using these standard algorithms?
|
||||
|
||||
Certainly. We will see how to find the shortest path from the source to the destination using DFS.
|
||||
|
||||
Let's look at how can we solve it using DFS.
|
||||
|
||||
|
||||
### Solution using DFS:
|
||||
|
||||
**Algorithm:** DFS approach is very simple.
|
||||
|
||||
- Start from the source vertex
|
||||
- Explore all the vertices adjacent to the source vertex
|
||||
- For each adjacent vertex, If it satisfies the relaxation condition then update the new distance and parent vertex
|
||||
- Then recurse on it, by considering itself as the new source.
|
||||
|
||||
**Relaxation** means if you reach the vertex with less distance than encountered before, then update the data. **Parent vertex** means the vertex by which the particular vertex is reached.
|
||||
|
||||
This way DFS will explore all the possible paths from the source vertex to the destination vertex and will find out the shortest path.
|
||||
|
||||
Here in the code, we will represent the graph using adjacency list representation:
|
||||
|
||||
```c++
|
||||
#include <bits/stdc++.h>
|
||||
using namespace std;
|
||||
#define MAX_DIST 100000000
|
||||
|
||||
// Function to print the required path
|
||||
void printpath(vector<int>& parent, int vertex, int source, int destination)
|
||||
{
|
||||
if(vertex == source)
|
||||
{
|
||||
cout << source << "-->";
|
||||
return;
|
||||
}
|
||||
printpath(parent, parent[vertex], source, destination);
|
||||
cout << vertex << (vertex==destination ? "\n" : "-->");
|
||||
}
|
||||
|
||||
void DFS(int source, int destination, vector<vector<pair<int,int> > > &graph, vector<int> &distances, vector<int> &parent)
|
||||
{
|
||||
// When we reach at the destination just return
|
||||
if(source == destination)
|
||||
return;
|
||||
|
||||
// Do DFS over all the vertices connected
|
||||
// with the source vertex
|
||||
for(auto vertex: graph[source])
|
||||
{
|
||||
// Relaxation of edge:
|
||||
// If the distance is less than what we
|
||||
// have encountered uptil now then update
|
||||
// Distance and Parent vertex
|
||||
if(distances[vertex.second] > distances[source] + vertex.first)
|
||||
{
|
||||
distances[vertex.second] = distances[source] + vertex.first;
|
||||
parent[vertex.second] = source;
|
||||
}
|
||||
|
||||
// Do DFS over all the vertices connected
|
||||
// with the source vertex
|
||||
DFS(vertex.second, destination, graph, distances, parent);
|
||||
}
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
// Number of vertices in graph
|
||||
int n = 6;
|
||||
|
||||
// Adjacency list representation of the
|
||||
// Directed Graph
|
||||
vector<vector<pair<int, int> > > graph;
|
||||
|
||||
graph.assign(n + 1, vector<pair<int, int> >());
|
||||
|
||||
// Now make the Directed Graph
|
||||
// Note that edges are
|
||||
// in the form (weight, vertex ID)
|
||||
graph[1].push_back( make_pair(1, 2) );
|
||||
graph[1].push_back( make_pair(6, 2) );
|
||||
graph[2].push_back( make_pair(1, 4) );
|
||||
graph[4].push_back( make_pair(1, 3) );
|
||||
graph[3].push_back( make_pair(1, 5) );
|
||||
graph[2].push_back( make_pair(7, 5) );
|
||||
graph[4].push_back( make_pair(3, 6) );
|
||||
|
||||
// Array to store the distances
|
||||
vector<int> distances(n+1, MAX_DIST);
|
||||
|
||||
// Array to store the parent vertices
|
||||
vector<int> parent(n+1, -1);
|
||||
|
||||
int source = 1, destination = 5;
|
||||
|
||||
distances[source] = 0;
|
||||
|
||||
// Do DFS
|
||||
DFS(source, destination, graph, distances, parent);
|
||||
|
||||
int shortest_distance = distances[destination];
|
||||
|
||||
// To print shortest_distance
|
||||
cout << shortest_distance << endl;
|
||||
|
||||
// To print the path of the shortest_distance
|
||||
printpath(parent, destination, source, destination);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
### Time Complexity of DFS
|
||||
As DFS explores all possible paths from the given source vertex to the destination vertex, this may lead to exponential time complexity in a very dense graph.
|
||||
|
||||
So, our DFS approach is not efficient. What next?
|
||||
|
||||
We have a very interesting and elegant algorithm to solve the problem named " **Dijkstra's Algorithm**". This is the algorithm whose variants are used by most of the path finding applications.
|
||||
|
||||
## Dijkstra's Algorithm:
|
||||
|
||||
Dijkstra's Algorithm solves SSSP.
|
||||
|
||||
Dijkstra's Algorithm is an iterative algorithm similar to **BFS**, but here we have a little twist.
|
||||
|
||||
**Algorithm:**
|
||||
|
||||
1. Mark the distance between the source and all other vertices to $\infty$ and assign all the parent vertices to some sentinel (not used value).
|
||||
2. The set is a collection of vertices which is empty at the start of the algorithm.
|
||||
3. Set the distance between source to source as 0 and add the source vertex to the set.
|
||||
4. Find the minimum distance vertex from the set and erase it from the set. Mark it as processed. let this vertex be $A$.
|
||||
5. Explore all the edges connected to $A$.
|
||||
6. If the edge is connected to the unprocessed vertex and it satisfies the relaxation condition below, then relax that edge and insert the vertex into the set.
|
||||
**Relaxation Condition:** Let the edge be $A-u$,
|
||||
$$\text{Distance}[u] < \text{Distance}[A] + \text{EdgeWeight}(A,u)$$
|
||||
4. If the set is empty, then stop the algorithm.
|
||||
5. Otherwise, repeat from step 3.
|
||||
|
||||
In Dijkstra's Algorithm, we explore the vertices in the way BFS does, however here we have to find the minimum distance vertex from the set.
|
||||
|
||||
Which data structure can help us find the minimum distance vertex from the set?
|
||||
|
||||
**Priority Queue** is the data structure which achieves this goal in an efficient manner $\mathcal{O}(\log n)$.
|
||||
|
||||
**Visualization:**
|
||||
|
||||
- Here cloud represents the processed nodes - the nodes whose final shortest distance is found.
|
||||
- Solid lines represent the edges that are discovered.
|
||||
- Numbers in square brackets represent the current distance of that vertex from the source vertex.
|
||||
|
||||
|
||||
1. Start from the source vertex 1. 
|
||||
2. Vertex 1 discovers vertices 2 and 3. It consequently does the relaxation and adds vertices 2 and 3 in the set.
|
||||

|
||||
3. The minimum distance vertex in the set is vertex 2. So vertex 2 will be the next source vertex.
|
||||
|
||||
It will discover vertices 5 and 4.
|
||||
|
||||
Now vertex 2 is added to the cloud as it is processed.
|
||||

|
||||
4. The next minimum distance vertex is vertex 4.
|
||||
It relaxes both 3 and 6. Then vertex 4 will be added to the cloud.
|
||||

|
||||
5. Next vertex will be 3. It relaxes 5.
|
||||

|
||||
6. Now there will not be any more relaxations.
|
||||
All the vertices in the priority queue will dequeue without adding any new vertex to the set.
|
||||

|
||||
|
||||
Now we have found the shortest distances to all the vertices from the given source vertex.
|
||||
|
||||
We can use parent array to store parent of the given vertex, and then we can find out the shortest path for any vertex.
|
||||
|
||||
```c++
|
||||
#include <bits/stdc++.h>
|
||||
using namespace std;
|
||||
#define MAX_DIST 100000000
|
||||
|
||||
// Function to print the required path
|
||||
void printpath(vector<int>& parent, int vertex, int source, int destination)
|
||||
{
|
||||
if(vertex == source)
|
||||
{
|
||||
cout << source << "-->";
|
||||
return;
|
||||
}
|
||||
printpath(parent, parent[vertex], source, destination);
|
||||
|
||||
cout << vertex << (vertex==destination ? "\n" : "-->");
|
||||
}
|
||||
|
||||
|
||||
// Dijkstra's Algorithm
|
||||
int Dijkstra_Algo(vector<vector<pair<int, int> > >& Graph,
|
||||
int src, int target, vector<int> & distances, vector<int> & parent)
|
||||
{
|
||||
|
||||
// Minimum Priority Queue to keep track of the discovered
|
||||
// vertex which has the minimum distance
|
||||
priority_queue<pair<int, int>, vector<pair<int, int> >,
|
||||
greater<pair<int, int> > > container;
|
||||
|
||||
// To check whether vertex is in the cloud
|
||||
vector<bool> processed(Graph.size());
|
||||
|
||||
// Start with source vertex
|
||||
// Push the source vertex in the
|
||||
// Priority Queue
|
||||
container.push(make_pair(0, src));
|
||||
|
||||
// Assign distance to source as 0
|
||||
distances[src] = 0;
|
||||
|
||||
|
||||
while (!container.empty()) {
|
||||
|
||||
// Pop the least distance vertex from the Priority Queue
|
||||
pair<int, int> temp = container.top();
|
||||
int current_src = temp.second;
|
||||
|
||||
// Pop the minimum distance vertex
|
||||
container.pop();
|
||||
|
||||
processed[current_src] = true;
|
||||
// current source vertex
|
||||
for (auto vertex : Graph[current_src]) {
|
||||
|
||||
// Distance of the vertex from its
|
||||
// temporary source vertex
|
||||
int distance = distances[current_src] + vertex.first;
|
||||
|
||||
// Relaxation of edge
|
||||
if (!processed[vertex.second] && distance < distances[vertex.second]) {
|
||||
|
||||
// Updating the distance
|
||||
distances[vertex.second] = distance;
|
||||
|
||||
// Updating the parent vertex
|
||||
parent[vertex.second] = current_src;
|
||||
|
||||
// Adding the relaxed edge in the prority queue
|
||||
container.push(make_pair(distance, vertex.second));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// return the shortest distance
|
||||
return distances[target];
|
||||
}
|
||||
int main()
|
||||
{
|
||||
// Number of vertices in graph
|
||||
int n = 6;
|
||||
|
||||
// Adjacency list representation of the
|
||||
// Directed Graph
|
||||
vector<vector<pair<int, int> > > graph;
|
||||
|
||||
graph.assign(n + 1, vector<pair<int, int> >());
|
||||
|
||||
// Now make the Directed Graph
|
||||
// Note that edges are
|
||||
// in the form (weight, vertex ID)
|
||||
graph[1].push_back( make_pair(1, 2) );
|
||||
graph[1].push_back( make_pair(6, 2) );
|
||||
graph[2].push_back( make_pair(1, 4) );
|
||||
graph[4].push_back( make_pair(1, 3) );
|
||||
graph[3].push_back( make_pair(1, 5) );
|
||||
graph[2].push_back( make_pair(7, 5) );
|
||||
graph[4].push_back( make_pair(3, 6) );
|
||||
|
||||
// Array to store the distances
|
||||
vector<int> distances(n+1, MAX_DIST);
|
||||
|
||||
// Array to store the parent vertices
|
||||
vector<int> parent(n+1, -1);
|
||||
|
||||
// For example destination is taken as 5
|
||||
int source = 1, destination = 5;
|
||||
|
||||
distances[source] = 0;
|
||||
|
||||
// Dijkstra's algorithm
|
||||
int shortest_distance = Dijkstra_Algo(graph, source, destination, distances, parent);
|
||||
|
||||
// To print shortest_distance
|
||||
cout << shortest_distance << endl;
|
||||
|
||||
// To print the path of the shortest_distance
|
||||
printpath(parent, destination, source, destination);
|
||||
|
||||
return 0;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
## Time Complexity of Dijkstra's Algorithm:
|
||||
|
||||
1. $\mathcal{O}(|E|)$ time to make the Weighted Directed Graph.
|
||||
2. $\mathcal{O}(|E| + |V|)$ can be taken by the while loop which is similar to BFS time complexity.
|
||||
3. $\mathcal{O}(\log |V|)$ time to insert the relaxed vertex in the priority queue.
|
||||
|
||||
So the overall complexity of the Dijkstra's Algorithm will be
|
||||
$$\mathcal{O}((|E| + |V|) \times \log(|V|))$$
|
||||
|
||||
Here $|E|$ represents the number of edges in the graph and $|V|$ represents the number of vertices in the graph.
|
||||
|
||||
|
||||
## Limitation of Dijkstra's Algorithm:
|
||||
|
||||
When there are negative weight edges in the graph, then Dijkstra's algorithm does not work.
|
||||
|
||||
Example:
|
||||

|
||||
|
||||
It will find the path from $a$ to $c$ incorrectly.
|
||||
|
||||
What if there is a negative cycle in the graph?
|
||||
|
||||
**Negative Cycle:** Cycle in which sum of the weights of the edges is negative.
|
||||
|
||||
When there is any negative cycle in the graph then Dijkstra's algorithm will run forever, because then we can reach the affected vertices in negative infinite cost.
|
||||
|
||||
Note that the graph, we have used, is connected. If you have a vertex which is not connected, then you cannot find the shortest distance to it!
|
||||
|
||||
## **Applications of Dijkstra's algorithm:**
|
||||
|
||||
|
||||
1. One very famous variant is the "Widest Path Finding Algorithm", which is an algorithm to finding a path between two vertices of the graph **maximizing the weight of the minimum-weight edge in the path**.
|
||||
|
||||
In the practical application, this problem can be seen as a graph with routers as its vertices and edges representing bandwidth between two vertices. Now if we want to find the maximum bandwidth path between two places in the internet connection, then this algorithm is useful which is highly based on Dijkstra's Algorithm.
|
||||
|
||||
2. A widely used application of the shortest path algorithm is in network routing protocols "Routing protocol".
|
||||
|
||||
## Other Shortest Path Finding Algorithms:
|
||||
|
||||
1 Bellman-Ford Algorithm
|
||||
2. Using Dynamic Programming
|
||||
3. All Pair Shortest Path Algorithm - **Floyd-Warshall Algorithm**, which finds the shortest path between every pair of vertices.
|
||||
|
||||
Reference in New Issue
Block a user